
- Every integration was a small engineering project
- One spine for every event, configured not coded
- What actually happens under the hood
- A workflow is JSON, not a codebase
- Why “agentic” here isn’t a buzzword
- A dry-run that runs the real thing — safely
- Observability is built in, not bolted on
- One platform, one conversation
IRIS is a no-code data pipeline platform. A webhook, a cron tick, a Kafka message, or a database change comes in — and a working integration comes out. No glue services. No deploy. An agent builds the pipeline with you, a sandbox proves it, and every run is observable from the same screen.
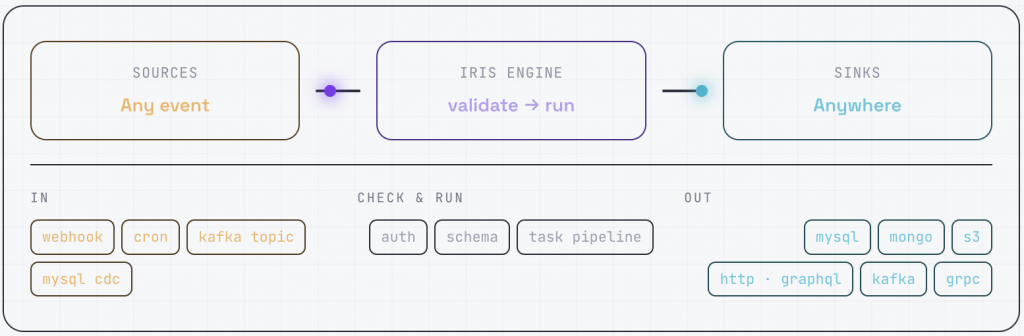
IRIS turns any inbound event into a running integration without writing a service. You describe the workflow as JSON tasks — or let the agent write them from a chat — validate against real auth and schema, dry-run it in a sandbox, and ship. The flagship proof: channel integration, courier onboarding, and courier cloning now run end-to-end from a chat window in under 30 minutes, with an approval gate and traces built in.
The problem we set out to kill
Every integration was a small engineering project
Connecting a sales channel, onboarding a courier, or wiring one more system into the order flow always meant the same thing: a new endpoint, a new consumer, bespoke transform code, a deploy, and a fresh place for bugs to hide. Multiply that by every partner and every event type and you get a backlog that only engineers can drain.
The typical path looked like this:
- An intake document lands — fields, mappings, auth, rate cards, status maps.
- Someone translates it into code and config across several services.
- Someone else reviews it and catches divergences by eye.
- It ships — and then the edge cases surface: a bad status map, a missing postcode set, a weight-band mismatch.
- Debugging means hopping across logs in several systems to answer one question: what actually went wrong?
The failure modes were exactly the kind humans are bad at catching by hand: silent divergences and config drift. And the unit of work was always a code change — the slowest, riskiest unit there is.
The shift
One spine for every event, configured not coded
IRIS collapses all of that into a single pipeline spine. Whatever the source — a webhook at the edge, a scheduled tick, a message on a Kafka topic, or a row change streamed off MySQL — it enters the same path: authenticate → validate → run a task definition → persist & trace. The integration is data, not a service.
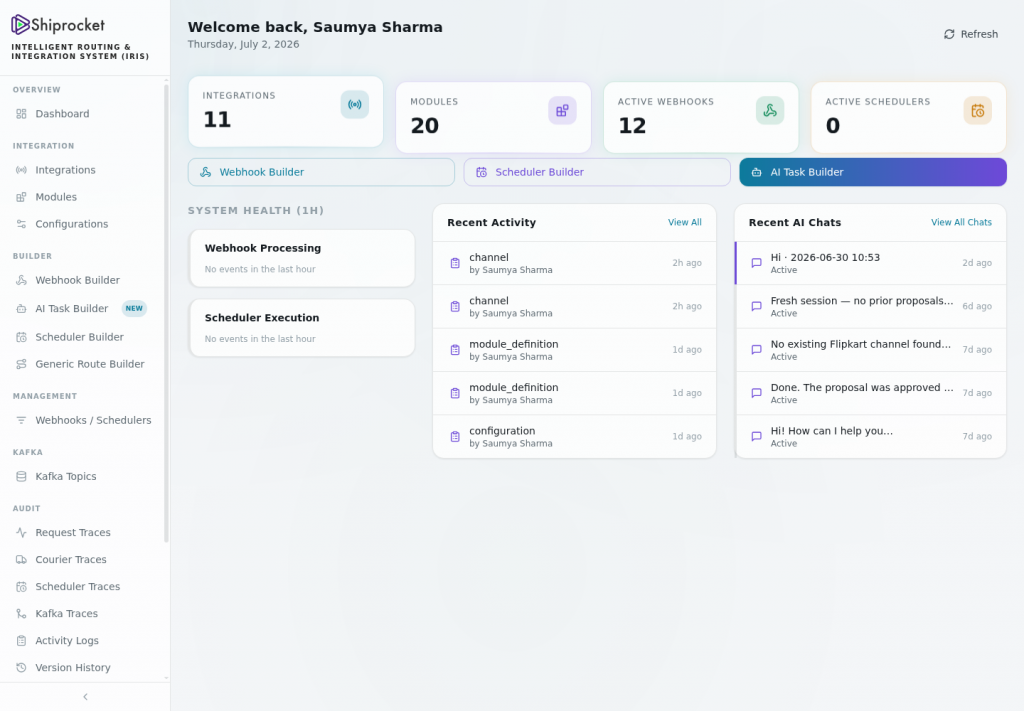
The IRIS console. Integrations, modules, webhooks, schedulers, live system health, and recent agent runs — one surface for the whole platform. Redact names, activity authors, and chat titles before publishing.
Ingest anything
Four doors, one path
Webhooks, cron schedules, Kafka topics, and MySQL CDC all land in the same validate-then-execute pipeline. New source, same spine.
Compose, don’t code
~130 task primitives
Fetch, transform, branch, loop, call HTTP/GraphQL/gRPC, publish Kafka, write MySQL / Mongo / S3 — as a JSON DAG, no redeploy to change it.
Prove before you ship
Dry-run sandbox
Run the real pipeline with every mutating step short-circuited. See the trace, confirm the shape, then go live for real.
Trust by default
Observed end to end
Every run emits a step-by-step trace to one place. When something breaks, you read the trace — you don’t correlate five dashboards.
Three of our most effort-heavy workflows now run entirely on this spine — driven by the agent, from chat:
| Workflow | What IRIS does | Old effort | New effort |
|---|---|---|---|
| Channel integration | Connect a sales channel end-to-end — order mapping, status mapping, sync rules. | ~days | <30 min |
| New courier integration | Onboard a courier from scratch — serviceability, zone rates, status maps, API wiring. | ~a week | <30 min |
| Courier cloning | Spin up a variant from a parent courier, every divergence surfaced and confirmed. | ~a week | <30 min |
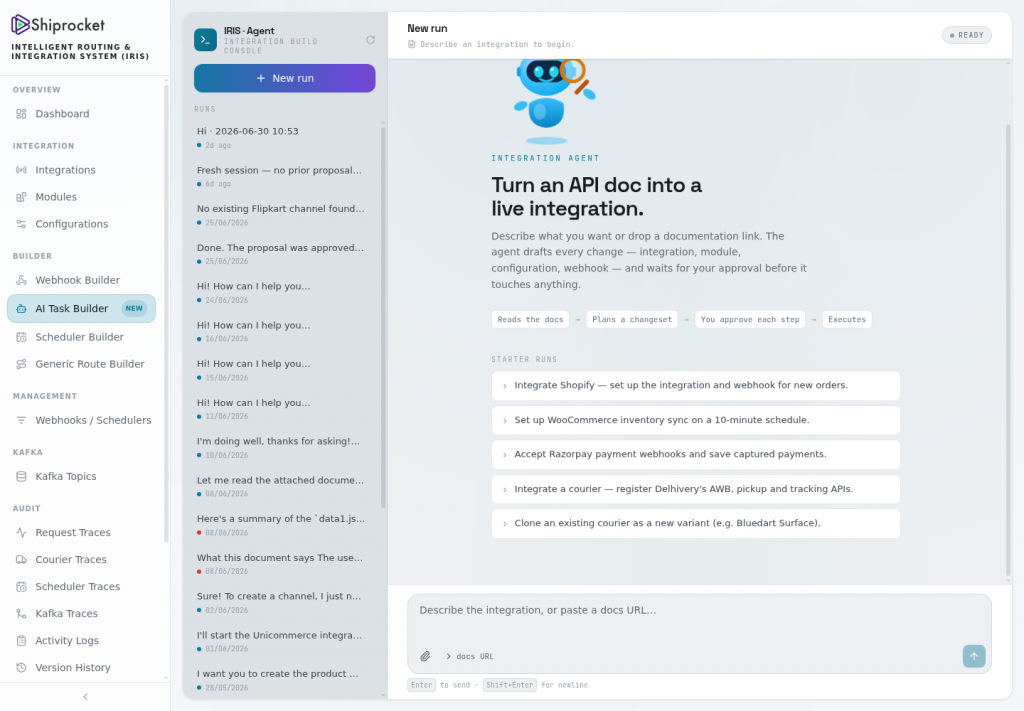
Architecture
What actually happens under the hood
At the platform level, every event follows the same journey. The agent adds a deliberate loop on top of it for mutating work — plan → preview → verify → gate → execute → observe — where no stage is skippable ceremony.
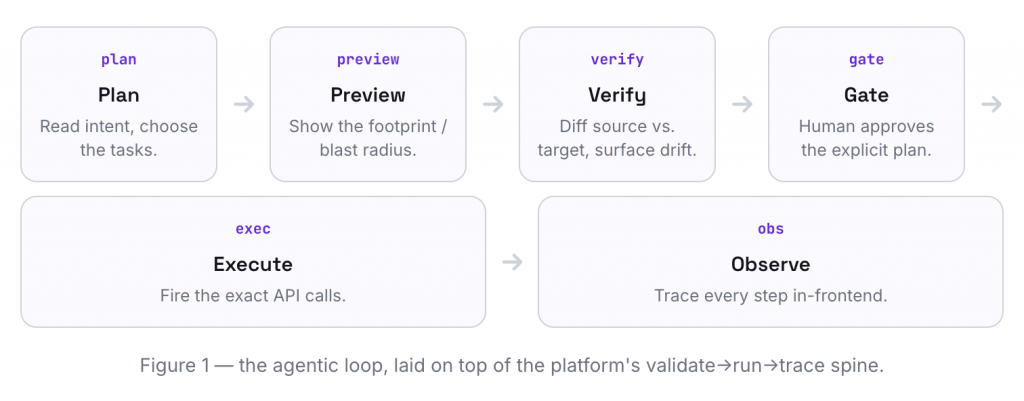
Under that loop, the platform is a small set of cooperating services:
Trace store — every run streams a step timeline into Elasticsearch, read back by the trace views.
Edge — captures webhooks, checks the allow-list, publishes to Kafka.
Consumers — one binary, several roles (async, sync, scheduler, kafka-topic, courier) each running the same task-definition executor.
Registration API — the panel’s backend, plus the in-process agent runtime.
The engine
A workflow is JSON, not a codebase
Every pipeline is a task definition: a DAG of typed steps wired by depends_on. Steps read each other’s output through a small template language, so a change is an edit to config — never a redeploy.
// a task references an earlier task's result by name
{
"type": "fetch_http",
"url": "https://api.partner.com/orders/{{input.payload.order_id}}",
"headers": { "Authorization": "Bearer {{tasks.auth.result.token}}" },
"depends_on": ["auth"]
}Template roots cover everything a step needs: {{input.*}}, {{tasks.X.result.*}}, {{loop_var}}, {{NOW}}. And the catalog of step types spans plumbing to channel-grade primitives:
~130 step types in all. A pre-execution validator rejects unsafe or ill-formed definitions before anything runs — a raw delete without a where, a raw query without params, a dangling {{tasks.X}} reference not declared in depends_on.
Integration as a conversation
Why “agentic” here isn’t a buzzword
A scripted automation encodes a fixed flow. An agent is given a goal, a set of tools — the platform’s own APIs — and guardrails, and it composes the steps to reach the goal. That distinction has real consequences on this platform:
- We train the agent to perform, rather than hard-coding every branch. It improves with every channel and courier it touches.
- New variations don’t need new scripts. A courier with a different serviceability model or status map is handled by the same reasoning over the same tools.
- The human stays on the decisions — the footprint preview, the verification, and the approval gate are exactly where judgment belongs.
The design principle, stated plainly: automate the mechanics, keep the human on the decisions.
The approval gate — a change contract, not a leap of faith
Nothing mutating runs unattended. Before execution the agent lays out an explicit change contract:
- what will be replicated from the source,
- what will diverge, and
- the exact API calls it intends to fire.
Only when you reply “proceed” does it execute. This is the single most important safety property: the human approves the plan, and the plan is explicit.
Prove it first
A dry-run that runs the real thing — safely
Before a pipeline touches production, IRIS runs it in a sandbox: the actual task definition executes, but every mutating step short-circuits and returns a synthesized result stamped dry_run: true. Writes don’t write, external POSTs don’t post, transactions don’t commit — yet you get a full, real trace of what would happen.
Dry-run traces are tagged and hidden from the default trace views, with a one-click “show dry-runs” toggle.
Sample input is auto-generated from the schema — or replayed from the latest real trace.
Runaway backstops: a wall-clock deadline, clamped loop iterations, clamped pagination and query limits.
The part we’re proudest of
Observability is built in, not bolted on
Speed is the headline, but trust is the real product. When something breaks, you don’t dig through logs across five systems — you see it right there in the frontend:
- what went wrong,
- what the system is actually saying, and
- the full trace of the run and every call it made.
Every flow — webhook, scheduler, and kafka-topic — writes a step timeline to its own trace surface, all readable from the same panel where the work was launched. That collapses the debugging loop from “open five dashboards and correlate timestamps” to “read the trace the platform already surfaced.”
What this points to
One platform, one conversation
The bigger idea is a single platform that spans integration → verification → execution → observability — a place where you stand up a channel or a courier, prove it’s correct, ship it, and watch it, all in one conversation.
This also changes who can do the work: LOps, Tech Support and Product teams can now integrate systems themselves, with the AI agent handling the heavy lifting — no engineering queue required.
That’s the direction: no-code, but with an agent behind it, and a human on the decisions that matter.