
Shiprocket is a commerce enabler for thousands of merchants and is helping businesses grow exponentially. But how? At Shiprocket, we are continuously expanding our services to simplify shipping, fulfillment, and marketing for businesses of all sizes. Through our comprehensive solutions including domestic and international shipping, hyperlocal deliveries, warehousing, and express delivery options, we are empowering merchants to manage their logistics with ease and efficiency. But in today’s fast-paced eCommerce world, it’s not just about providing services, scaling is essential.
With millions of transactions processed and shipments tracked every day, our ability to scale ensures reliability, speed, and cost-efficiency for every order. Whether it’s a small business looking to expand or a large enterprise managing high volumes, Shiprocket’s platform is built to handle the growing demands of modern eCommerce, enabling our customers to scale effortlessly.

Scaling with ease at Shiprocket
Shiprocket’s ability to handle millions of eCommerce transactions every month is driven by a robust technological backbone built to scale and perform under immense demand. From lightning-fast response times to an unwavering commitment to reliability, our platform processes and monitors countless shipments, transactions, and data points every day. This ensures that businesses and their customers have a seamless experience.
Here’s a glimpse into the numbers that define the sheer scale and efficiency of Shiprocket’s operations:
| Monthly API Hits | 4.5B |
| Incoming and outgoing webhooks daily | >20M |
| Serviceability requests daily | >10M |
Events processed by Kafka Backbone daily | 400M |
| Reads/Writes on in memory data stores monthly | >500M |
| Monthly Transactions Count | >10M |
| Number of messages sent daily | ~4M |
| Amount of Inserts/Updates/Deletes on DBs daily | 3.5TB |
| Peak writes per second on the DBs | 29K |
| Reads/writes on cache monthly | 970M |
| CDC log size handled by data platform daily | 450GB |
| No of DB instances supporting the business | 30+ |
| Volume of logs ingested across products daily | ~2TB |
Shiprocket’s Tech stack
Handling millions of transactions and shipments daily requires a sophisticated and resilient tech stack. At Shiprocket, we’ve built a robust ecosystem of cutting-edge technologies carefully designed to handle the complexities of modern eCommerce logistics. From advanced algorithms for route optimisation to real-time tracking and machine learning-driven decision-making, our tech stack ensures smooth operations at every stage of the fulfillment process.
Here’s a look at the diverse technologies and tools that empower Shiprocket to deliver efficiency, reliability, and innovation across its platform:

When it comes to scaling an application as vast as Shiprocket, two critical pillars hold everything together- APIs and Databases. These components form the backbone of our platform, ensuring that millions of transactions and data points flow smoothly across the system every day.
APIs allow us to integrate seamlessly with third-party platforms, automate processes, and enable real-time communication between different services, driving efficiency at every level. Meanwhile, our databases are designed to handle vast amounts of data, ensuring that every query, order, and shipment detail is stored, retrieved, and processed with lightning-fast speed and accuracy. Together, they provide the foundation that enables Shiprocket to scale dynamically, ensuring reliability and performance, no matter how fast we grow.
Scaling APIs
Before diving into how our APIs are structured and scaled to meet growing demands, let’s first take a look at what a typical order journey looks like within our ecosystem.
- The order journey:
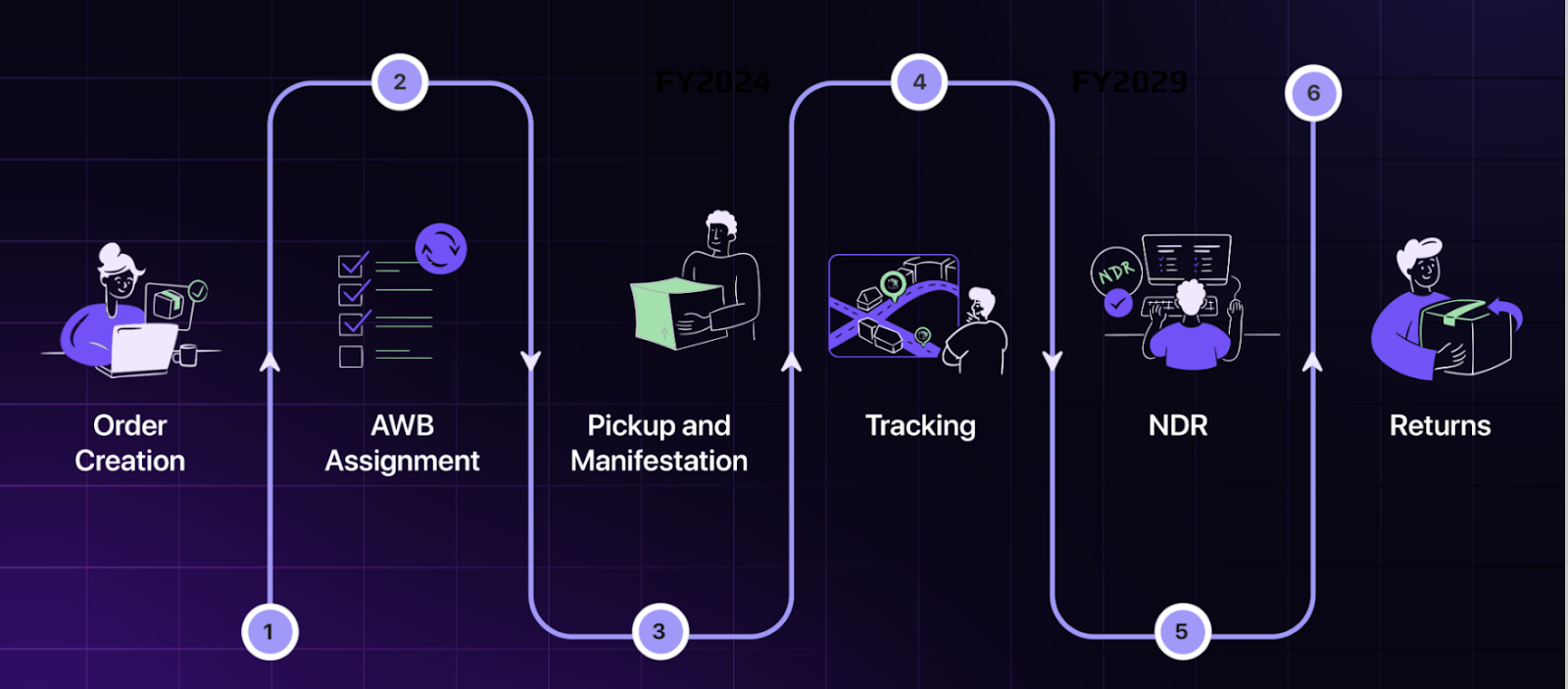
- Order Creation: The seller creates an order in our system either via API integration or using our seller panel, and the system captures all necessary details such as shipping address, payment, and items to be shipped.
- AWB Assignment: An Air Waybill (AWB) number is generated and assigned to the order, enabling tracking and facilitating shipment with the carrier.
- Pickup and Manifestation: The logistics partner picks up the package from the seller, and a shipping manifest is generated, confirming the order details for transit.
- Package Tracking: Real-time tracking is enabled as the package moves through various stages of transit until delivery, providing visibility to both the seller and the customer.
- NDR (Non-Delivery Report): If delivery fails (e.g., incorrect address, customer unavailable), a Non-Delivery Report is generated, and corrective actions like rescheduling are taken.
- Returns: If the customer returns the order, the package is collected and tracked back to the seller, completing the return process.
Multiple logically separated microservices manage each of these steps. These microservices communicate with each other through an event-driven architecture. As each stage in the order process triggers events, other services listen to and respond to these events. This approach allows for improved scalability and performance while ensuring that different parts of the system can work in harmony.
Microservices and event-driven architecture
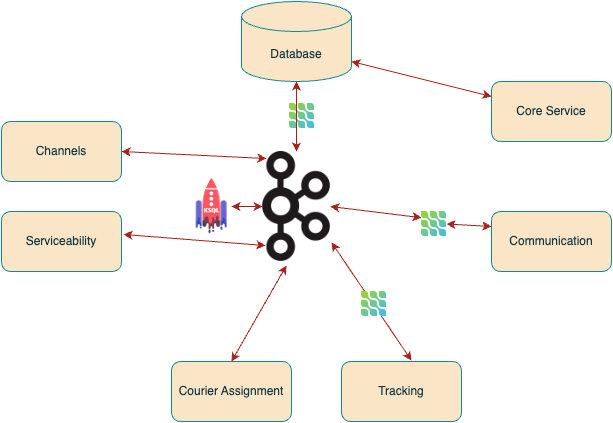
As you can see in the image above, we have separated the logical units of our entire application into different microservices that can scale and operate independently.
The use of Apache Kafka helps in real-time communication between the services, and each event is consumed by multiple services without performance bottlenecks, making sure orders move smoothly through the system.
Let’s get into more details one by one.
1. Decoupling of Events
In an event-driven architecture, decoupling events is a fundamental design principle. Decoupling involves separating different parts of the system so they work independently while still communicating through events. This approach boosts flexibility and scalability because components don’t need to know about each other’s internal workings; they only need to listen for relevant events.
For example, when a tracking number is assigned to an order in Shiprocket, instead of directly updating the tracking and communication services, an event like AwbAssigned is broadcast. The tracking service and the communication service used for notifying the customer can subscribe to this event and act accordingly. This decoupling enables services to evolve independently, minimises dependencies, and improves fault tolerance, as services can continue functioning even if one component fails temporarily. It also enhances scalability, allowing each service to scale independently based on demand.
2. Events Produced by the Applications are Persisted as Database Upserts
In this architecture, applications produce events whenever something significant occurs, such as creating a new order, updating shipping details, or processing a payment. These events flow through the system and ultimately result in updates or inserts (upserts) in the database.
Using upserts, which is a combination of update and insert ensures that, even if an event is processed multiple times due to retries or failures, the database remains consistent. Upserts help avoid issues like duplicate entries or inconsistent data. For example, if an OrderShipped event is processed more than once, it will only update the shipment status in the database without creating a new record. Persisting events as upserts ensure the latest state is always reflected in the database, enabling robust workflows where multiple events can affect the same data.
3. Binary Logs are the Source of Truth
In a robust event-driven system, binary logs serve as the source of truth. Binary logs or binlogs are a record of all database changes, capturing every transaction and modification, such as inserts, updates, and deletes that occur in the system. Tools like Debezium capture these changes and stream them in real time, ensuring that every event and corresponding state change is reliably recorded.
Using binary logs as the source of truth means that even in the event of a system failure or component crash, the latest state can always be recovered by replaying these logs. In Shiprocket’s context, binary logs are essential for tracking every shipment, payment, or order event, ensuring that no data is lost during failures or delays. If a service doesn’t successfully process an event, the system can replay the event from the logs and reapply the changes.
Binary logs also provide a historical audit trail, offering system transparency and making debugging or recovery easier in case of discrepancies. Since logs record every system action, they can be used to rebuild the system’s state in case of a catastrophic failure or for real-time replication and synchronisation between systems.
Scaling databases
At Shiprocket, handling millions of daily transactions calls for a resilient, scalable database infrastructure. To meet these demands, we rely heavily on MySQL, which is valued for its reliability and adaptability in large-scale settings. However, as the volume of transactional data grows, simply scaling vertically by adding resources isn’t sufficient to manage the load effectively. This is where a hybrid approach of vertical and horizontal sharding becomes essential, ensuring both optimal database performance and reliability.
Vertical sharding
At Shiprocket, our expanding orders table held extensive details for each order, including attributes like order source, company ID, amount, payment mode, and customer information. As the number of orders grew, managing this large table became increasingly challenging, with performance issues arising during queries. We also observed a few additional factors:
- Many columns in the table stored text and JSON data that were rarely updated
- Searches on this data were infrequent
- Most of the data served a transactional purpose rather than requiring extensive querying
To address this, we implemented a logical restructuring: splitting the table into two parts, orders and orders_meta. The orders table now stores primary information that is frequently queried, while less-accessed data resides in the orders_meta table, which we moved to a separate database.
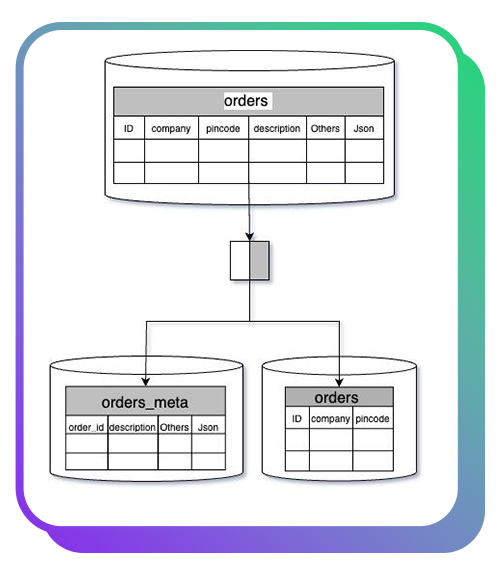
The above restructuring resulted in several key improvements:
- Enhanced performance for frequently queried data
- Reduced I/O and storage demands
- Simplified table maintenance and scalability
- Improved cache utilisation
Horizontal partitioning
At Shiprocket, we frequently encounter scenarios where data access is required at the seller level. Given that the volume of records can vary significantly among sellers, query performance often suffers when searching through a large table. Additionally, any updates made for a specific seller can result in the entire table being locked, further degrading performance.
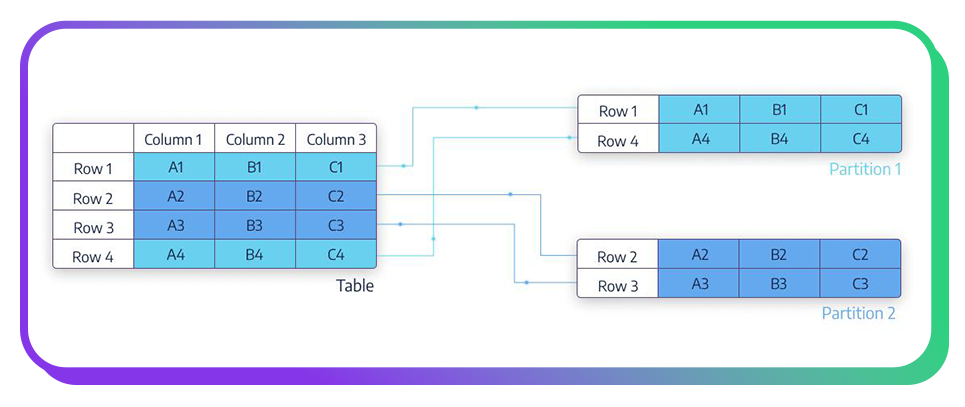
To address this issue, we partitioned our orders table into multiple partitions based on the company ID. This approach offers several benefits:
- Reduced Index Footprint: Smaller partitions lead to a more manageable index size, enhancing efficiency.
- Enhanced Query Performance: By focusing searches on specific partitions, we can significantly improve query response times.
- Simplified Maintenance: Managing smaller partitions simplifies tasks such as backups and data migrations.
- Minimized Table Locks: Smaller partitions mean that updates are less likely to lock the entire table, reducing contention.
- Isolation of Large Tables: Partitioning helps isolate large tables, making it easier to manage them without affecting overall system performance.
- Balanced Workload: Distributing data across multiple partitions helps balance the workload, preventing any single partition from becoming a bottleneck.
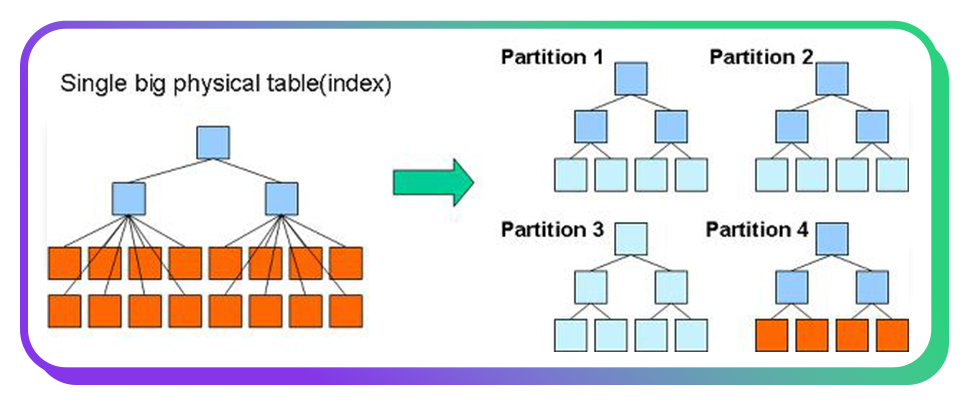
Horizontal sharding: The unconventional way
Our eCommerce business is growing exponentially, resulting in a dynamic influx of database. This also means that we encounter significant challenges in performance and maintenance. Despite our efforts to optimise tables and improve efficiency, the increasing size of the database resulted in persistent performance issues. A key factor motivating us to explore horizontal sharding was the realisation that older data is accessed infrequently, prompting us to rethink our database architecture.
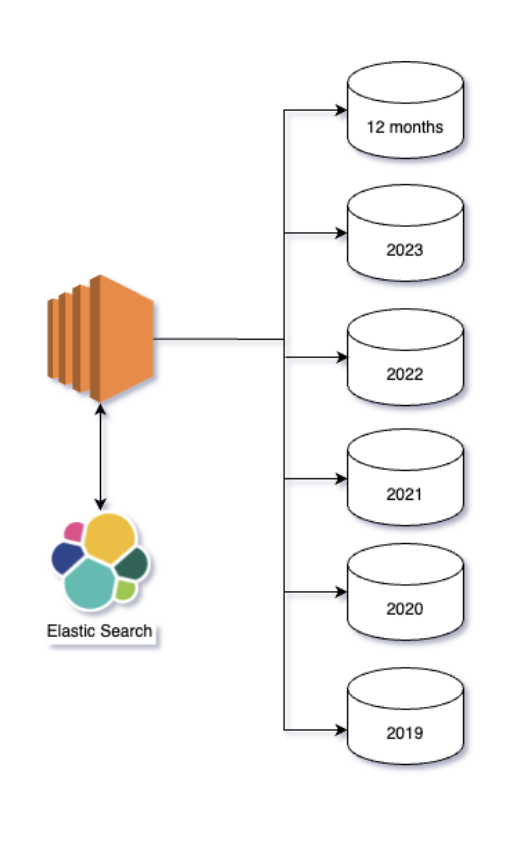
The need for horizontal sharding
After an order has been delivered, it becomes less frequently accessed, with sellers typically only revisiting older records for reporting or financial assessments. Understanding this pattern led us to a strategic decision: to horizontally shard our database by organizing it into separate databases for each year.
By keeping only the last 12 months of data in our active database and archiving older records into year-specific databases, we achieved significant performance improvements. This approach not only optimized query response times but also helped us maintain control over the size of our active database.
Addressing the need for historical data access
Even with our new sharding strategy, we recognized that sellers would still need access to older records for various purposes, including generating reports. To facilitate this, we implemented a metadata system using Elasticsearch.
When sellers initiate a search for older records, the query is first processed through Elasticsearch, which efficiently indexes the metadata of all records. Once the relevant data is identified, it is then fetched from the corresponding year-specific database. This dual approach allows us to ensure optimal database performance while still providing seamless access to historical data.
In an ever-evolving eCommerce landscape, Shiprocket remains steadfast in its commitment to delivering unparalleled logistics solutions. Our strategic focus on scalability through a robust tech stack, sophisticated microservices, and innovative database management not only empowers businesses to navigate their growth journeys with confidence but also ensures that we can efficiently handle millions of transactions daily.
At Shiprocket, we are not just facilitating logistics; we are driving the future of eCommerce. As we continue to innovate and adapt, our customers can trust that they are supported by a platform built for reliability, speed, and efficiency.