
At Shiprocket, innovation is at the core of everything when it comes to delivering seamless logistics solutions that empower 2,50,000+ merchants to thrive in a competitive market. We are constantly evolving and reengineering our tools, strategies, and methodologies to increase efficiency and resolve emerging issues.
A crucial product of Shiprocket is Shiprocket Engage360, an all-in-one communication and customer engagement platform helps eCommerce businesses acquire customers, convert sales, drive repeat orders, and grow revenue. Through this product, we focus on marketing retention. This implies that our business relies heavily on counters data. Counters track a variety of metrics such as messages sent, delivered, read, orders placed, revenue generated, and more. Traditionally, our monolithic Play Framework-based system (written in Java) uses Redis for real-time counters. However, as we scaled and our data requirements evolved, we faced challenges that led us to revamp our entire counters architecture.
In this blog, we’ll walk through our journey of upgrading to a more flexible architecture using Kafka and PostgreSQL. We’ll also cover the technical challenges we faced, particularly around concurrency, data aggregation, and cost optimisation.

The Problem with Redis
Redis was initially the backbone of Shiprocket’s counters system. It’s in-memory structure allowed high-speed access to frequently updated data. However, as our requirements grew more complex, we started encountering several challenges:
Key Challenges:
- Lack of Support for Long-Term Data: Redis, being an in-memory data store, is designed for fast access to short-lived data. However, for our use case, we needed to store and query counters for up to a year or more, which led to increasing memory consumption.
- Code Coupling: Our system was heavily coupled with Redis. A number of microservices directly manipulated Redis to update counters, leading to tight dependencies and hard-to-manage code.
- Redis Version Limitation: When upgrading Redis to a version that supported ACLs, we found that Play framework libraries for Redis didn’t support the new version. This forced us to reconsider Redis as the sole solution for managing counters.
- Single-Threaded Nature: Redis is single-threaded, meaning it can only process one command at a time. In high-concurrency situations, there’s a queue of commands waiting to be executed, causing delays and potential data conflicts.
- Locking Overhead: Implementing locks (such as Redis transactions with WATCH and MULTI commands) helped us avoid race conditions but introduced overhead, which can significantly degraded our performance under heavy loads.
Given these limitations, we decided to redesign the Counter architecture, focusing on scalability, flexibility, and cost efficiency.
Shiprocket’s Solution: Kafka as a Message Queue and PostgreSQL as a Cache
The Architecture
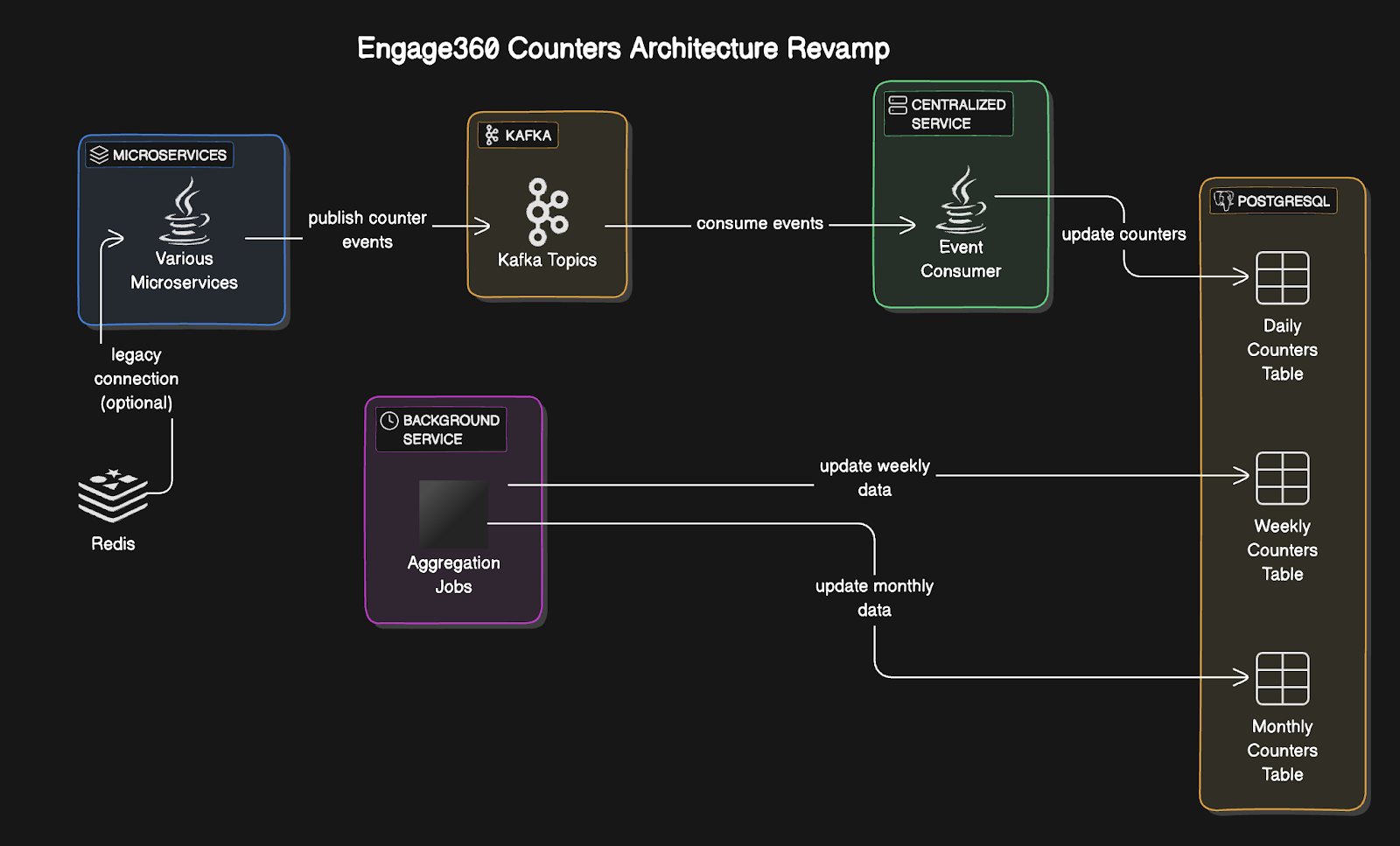
To address the above issues, we decided to break the coupling with Redis and introduce a more modular system using Kafka for message queueing and PostgreSQL as a caching and aggregation layer. Here’s how the new architecture works:
- Event-Driven Counters: Instead of directly updating Redis, each microservice now publishes counter events (such as “message sent”, “order placed”, etc.) to Kafka. This decoupled the microservices from Redis and centralised the handling of counters.
- Centralised Service: A centralised service listens to Kafka topics, consumes these counter events, and updates the counters in PostgreSQL. This service uses atomic operations to ensure that data integrity is maintained even during high concurrency.
- PostgreSQL for Long-Term Storage and Aggregation: Instead of relying on Redis for long-term data storage, we switched to PostgreSQL to store counters data. PostgreSQL allows us to persist data indefinitely and query it efficiently. Additionally, it provides powerful aggregation capabilities that help us derive insights from the counters.
Kafka: The Backbone of Event Handling
Using Kafka as a message queue solved multiple issues:
- Decoupling of Services: By publishing counter events to Kafka, microservices no longer need to be concerned with the underlying storage or caching mechanism. They just emit events, and the rest is handled asynchronously.
- High Throughput: Kafka’s ability to handle millions of events per second ensures that our system can scale as traffic increases. This is particularly useful during high-volume marketing campaigns when counter events spike.
- Data Durability: Kafka provides durability by persisting events on disk, ensuring that even if there are failures, counter events can be replayed and no data is lost.
Handling Concurrency Without Locks
One of the most significant technical challenges we faced was handling concurrency without locking. Imagine a scenario where multiple users are interacting with the same campaign, updating counters for “messages sent” or “orders placed” concurrently. In our new architecture, we leveraged the following techniques to handle concurrency:
- Atomic Updates: PostgreSQL’s support for atomic operations (like UPDATE … WHERE … RETURNING) allows us to ensure that even under concurrent access, each counter update is applied correctly. This avoids the need for explicit locks.
- Batch Updates: In cases where we expect a “thundering herd” effect (e.g., thousands of updates to the same counter), we aggregate these updates in-memory and apply them in batches to PostgreSQL. This reduces the number of write operations, further improving performance.
- Sharded Counters: For counters that are highly contended, we shard the data by splitting the counter into multiple rows based on criteria like user region or campaign ID. This distributes the write load and reduces contention on any single row.
Aggregation and Efficient Querying
With the new architecture, Shiprocket also introduced more efficient aggregation strategies. For some use cases, we needed to query counters data over a range of dates (e.g., how many messages were delivered in the last month). In other cases, we needed to update counters on a per-day basis. To handle these varying needs, we split the counters data across multiple tables in PostgreSQL:
- Daily Counters Table: This table stores counter values at a daily granularity. Every day, new rows are added with the counters for that day.
- Weekly and Monthly Tables: To optimise for queries that request counters over a week or month, we introduced pre-aggregated weekly and monthly tables. These tables are updated periodically (e.g., via a cron job), ensuring that queries for these time ranges are fast and efficient.
Benefits of the New Architecture
1. Cost Efficiency
One of the biggest wins with this new architecture is cost savings. Redis, while incredibly fast, becomes expensive when used to store large volumes of long-lived data. By moving to PostgreSQL, we’ve offloaded this data from Redis, reducing our overall memory consumption and cost. PostgreSQL, being disk-based, is much more cost-effective for storing large datasets over extended periods.
2. Scalability
With Kafka handling the event queue, our system can now handle spikes in traffic without becoming overloaded. Kafka’s partitioning mechanism ensures that even with millions of counter events per second, we can scale horizontally and maintain performance.
3. Improved Query Performance
By pre-aggregating data at daily, weekly, and monthly intervals, we’ve significantly improved the performance of queries that request counters over time ranges. These queries now hit smaller, pre-aggregated tables instead of scanning the entire dataset.
4. Flexibility
The decoupling of microservices from Redis means that our system is now much more flexible. We can easily swap out the underlying storage layer or add new processing logic without having to modify the microservices.
Drawbacks and Takeaways
While our new architecture solved many of the challenges we faced with Redis, it’s not without its downsides:
- Increased Complexity: Moving from a simple Redis-based system to a Kafka + PostgreSQL architecture introduces more components to manage and monitor. This added operational complexity, though we believe the benefits outweigh this cost.
- Delayed Response: While Redis provides near-instantaneous access to in-memory data, the combination of Kafka and PostgreSQL introduces a small amount of latency. For our use case, this is acceptable, but it may not be suitable for systems requiring real-time data updates.
- Maintenance Overhead: The aggregation jobs for weekly and monthly tables need to be carefully managed to ensure they run efficiently. This introduces some maintenance overhead, though we’ve mitigated this by making the jobs incremental.
Conclusion
Shiprocket’s step towards revamping the counters architecture was a necessary measure to ensure that our system could scale with growing business demands. By moving to a Kafka-based event-driven system with PostgreSQL for long-term storage and aggregation, we’ve achieved greater scalability, flexibility, and cost efficiency. This new architecture has not only solved our immediate challenges but also positioned us to handle future growth and evolving requirements.