
- The Plight of Cloud Management Costs: A Growing Challenge
- 1. Optimising Reserved Instances (RI) and Savings Plan Purchases
- 2. RDS, S3, WAF, and CloudFront Cost optimisation
- 3. EC2 Volume and Data Transfer optimisation
- 4. CloudWatch and Log Group optimisation
- 5. WAF optimisation
- 6. Leveraging Spot Instances
- 7. Real-Time Monitoring and Alerting with ELK and Grafana
- 8. Real-World Successes: Achieving Meaningful Cost Savings
- 9. GP2 vs GP3 for EBS Volumes: optimising Costs
- 10. Cost Reduction by Using NAT Instances Instead of NAT Gateways
- 11. Avoiding Cost with S3 Delete Markers: A 20L Lesson
- An Overview of Shiprocket’s Cost Optimisation Journey
- Lessons Learned from the Cost Optimisation Initiative
- Conclusion
In today’s fast-paced digital landscape, efficient cloud infrastructure management is paramount. Since its launch in 2017, Shiprocket has amassed a vast reservoir of data fueled by 12+ products, generating a massive influx on a day-to-day basis. With all this data stored in the cloud for seamless resource monitoring and Optimisation, a question loomed on us: What about the skyrocketing costs of maintenance and upgrades? As our operations grew, so did the need for a smarter and leaner approach to managing cloud expenses
Let us take you through the behind-the-scenes of how Shiprocket mastered cloud cost Optimisation and trust us, it’s a ride filled with smart tech, big wins, and a whole lot of savings!

The Plight of Cloud Management Costs: A Growing Challenge
Before implementing any cost optimisation strategies, we faced an all-too-common yet complex problem: the rapid and unpredictable growth of cloud costs. Cloud computing promises flexibility and scalability, and while these benefits are undeniable, they come with an often-overlooked burden – cost management.
When we decided to go ahead with the cloud, our focus was on scalability, redundancy, and reliability. We wanted to ensure that our customers could always depend on our services, regardless of spikes in demand or changes in traffic patterns. With time, however, we realised that achieving these goals came at an increasing cost. The problem wasn’t just the monetary aspect; it was also about understanding where the costs were coming from.
Key Issues in Pre-Optimisation Cloud Cost Management
While trying to get our hands on cost-optimisation, we faced multiple challenges.
- Lack of Visibility: One of our biggest challenges was understanding how much we were spending and why. We had multiple accounts, services across various regions, and different teams using cloud resources independently. Without the right monitoring and analytics tools, tracking what was driving up our monthly bills was nearly impossible.
- Uncontrolled Resource Sprawl: Like many organizations moving fast, we saw an unchecked proliferation of resources: EC2 instances, RDS databases, ELBs, and even S3 buckets. Instances were spun up for testing purposes but often left running, incurring ongoing costs. There were many unknown “zombie” resources that were unused but still billing us each month.
- Data Transfer Costs: With our services scattered across different regions and zones, data transfer costs grew exponentially. The lack of understanding around data flow and the associated charges made optimising these costs particularly daunting.
- Underutilized Reserved Instances: Although we initially invested in Reserved Instances (RIs) to save costs, we quickly found ourselves with misaligned RIs. Because our infrastructure and workloads changed fast, many RIs were underutilized or misallocated, leading to wasted potential savings.
- Log Management Chaos: Log generation was another major source of expense. CloudWatch, with its powerful metrics and storage capabilities, proved to be an essential tool. However, without actively managing retention policies and optimising what we needed to store, log storage costs spiraled out of control. In some cases, we were spending more on logging than actual operational activities!
- Developer Autonomy with Hidden Costs: While we value empowering our developers to take ownership of their environments, this often led to resources being spun up without considering costs. Developers experimented with EC2 instance types and scaling rules, and they even spun up powerful GPU instances, all without much awareness of the cost implications.
- Ineffective Scaling: Auto-scaling was initially intended to help us manage demand and reduce costs by dynamically adjusting to traffic. In practice, however, misconfigured scaling rules led to excessive nodes being spun up, increasing our costs far beyond what we could justify, especially during traffic spikes.
Our Struggle to Strike the Balance
The cumulative effect of the above mentioned issues was not only financial but also a strategic burden. We spent more time trying to understand our cloud costs rather than focusing on adding value to our business and customers. Monthly cloud bills became unpredictable, making managing budgets and planning for the future complex. This unpredictable and ever-increasing cost trajectory was unsustainable, prompting us to embark on our cost optimisation journey.
Our realisation was stark, without a deliberate and comprehensive cost management strategy, the benefits of cloud scalability and flexibility were overshadowed by the unpredictability of rising costs. We needed a unified approach that balanced growth with sustainability. That’s where our focus on optimising costs through careful planning, monitoring, and tooling began.
Our mission was clear: reduce cloud costs while maintaining high performance, security, and availability. What initially seemed like a straightforward goal soon unfolded into a complex and multi-faceted project that spanned across teams, services, and regions. In this blog, we’ll walk you through our journey, the challenges we faced, the solutions we implemented, and some personal stories from the trenches.
Our journey in cloud cost optimisation wasn’t just about a series of actions but a strategic approach that involved breaking down every aspect of our cloud usage to find efficiencies without compromising on service quality. We learned that while each cloud service offers immense flexibility, it also demands precise control and understanding to ensure we aren’t paying for what we don’t need. From leveraging cost-saving programs to fine-tuning storage and data transfer, each step was a significant piece of the puzzle.
In this blog, we’ll dive into how we approached Reserved Instances (RI) and Savings Plan Purchases, explored opportunities to optimise costs across RDS, S3, WAF, and CloudFront, and tackled challenges associated with EC2 Volumes and Data Transfers. We’ll also discuss our experiences in managing CloudWatch Log Groups, tweaking WAF rules, and embracing Spot Instances to dramatically reduce expenses.
Let’s start with our first major undertaking: Optimising Reserved Instances (RI) and Savings Plan Purchases, an essential component in our cost reduction journey.
1. Optimising Reserved Instances (RI) and Savings Plan Purchases
The Challenge: Managing RIs Across Multiple Accounts
As an organization with multiple AWS accounts, managing Reserved Instances (RIs) across these accounts was a significant challenge. We knew we could save a substantial amount by using RIs and Savings Plans (SP), but our problem was two-fold:
- Visibility: We lacked clarity on which instances were consuming RIs across accounts.
- Over-provisioning: Without accurate tracking, we occasionally found ourselves over-provisioning, thus reducing the potential cost savings.
Reason: Limitations of our cloud billing partner where we purchase our commitments from.
Our Solution: Centralized RI and SP Management
We developed a script to analyse instance usage across all AWS accounts, grouping instances by region, type, and availability. This allowed us to calculate the number of RIs we needed and compare it to our existing commitments.
Here’s a simplified version of the script that helps us manage RI and SP recommendations:
ri_list.py:
| # Dictionary to store aggregated data aggregated_data = {} # Read the data from the file with open(“reserved_instances_list.csv”, “r”) as file: for line in file: parts = line.strip().split(‘\t’) if len(parts) == 2: key = parts[0] value = int(parts[1]) if key in aggregated_data: aggregated_data[key] += value else: aggregated_data[key] = value # Print the aggregated results for key, value in aggregated_data.items(): print(f”{key}\t{value}”) |
ri_list_ec2_instances_count.py:
| # Dictionary to store aggregated data aggregated_data = {} # Read the data from the file with open(“ec2_instances_count.csv”, “r”) as file: for line in file: parts = line.strip().split(‘ ‘) if len(parts) == 2: key = parts[0] value = int(parts[1]) if key in aggregated_data: aggregated_data[key] += value else: aggregated_data[key] = value # Print the aggregated results for key, value in aggregated_data.items(): print(f”{key}\t{value}”) |
ri_list_reserved_instances_count.py:
| # Dictionary to store aggregated data aggregated_data = {} # Read the data from the file with open(“reserved_instances_count.csv”, “r”) as file: for line in file: parts = line.strip().split(‘ ‘) if len(parts) == 2: key = parts[0] value = int(parts[1]) if key in aggregated_data: aggregated_data[key] += value else: aggregated_data[key] = value # Print the aggregated results for key, value in aggregated_data.items(): print(f”{key}\t{value}”) |
main.py:
| #!/bin/bash aws ec2 describe-instances –filters “Name=instance-state-name,Values=running” –query ‘Reservations[*].Instances[*].[Tags[?Key==`Name`]|[0].Value,InstanceType]’ –output text | sort | uniq > ec2_instances_main_account.csv instance_names_file=”ec2_instances_main_account.csv” ignore_values_file=”ec2_instances_ignore.csv” IFS=$’\n’ read -d ” -r -a ignore_values < “$ignore_values_file” # Add values from missing_values.txt to ignore_values array based on conditions while read -r value; do if [[ $value == *”ECS”* || $value == *”ecs”* || $value == *”spot”* || $value == *”Spot”* ]]; then # Check if value is not already in ignore_values array if [[ ! ” ${ignore_values[@]} ” =~ ” $value ” ]]; then ignore_values+=(“$value”) echo “Added value ‘$value’ to ignore list.” echo “$value” >> “$ignore_values_file” fi fi done < “$instance_names_file” while IFS= read -r line; do grep -v “$line” ec2_instances_main_account.csv > ec2_instances_main_account_updated.csv mv ec2_instances_main_account_updated.csv ec2_instances_main_account.csv done < “$ignore_values_file” cat ec2_instances_main_account.csv | awk ‘{print $2}’ | sort | uniq -c | sed ‘s/^[ \t]*//’ | awk ‘{temp = $1; $1 = $2; $2 = temp}1’ > ec2_instances_count.csv python3 ri_list.py | sort | sed ‘s/\t/ /g’ > reserved_instances_count.csv awk ‘{print $1}’ reserved_instances_count.csv > reserved_instances_type.csv file_path=”reserved_instances_type.csv” # Use a for loop to read and print each line while IFS= read -r line; do reserved_instance=$(cat reserved_instances_count.csv | grep “$line” | awk ‘{print $2}’) ec2_instance=$(cat ec2_instances_count.csv | grep “$line” | awk ‘{print $2}’) if [ -z “$ec2_instance” ]; then ec2_instance=0 fi result=$(($reserved_instance – $ec2_instance)) if [ $result -gt 0 ]; then echo “RI Count is Greater than EC2 Count in $line Instance Type” grep -v “$line” ec2_instances_count.csv > ec2_instances_count_updated.csv mv ec2_instances_count_updated.csv ec2_instances_count.csv echo “$ec2_instance” awk -v line=”$line” -v ec2_instance=”$ec2_instance” ‘$1 == line {$2 -= ec2_instance}1’ reserved_instances_count.csv > reserved_instances_count_updated.csv mv reserved_instances_count_updated.csv reserved_instances_count.csv elif [ $result -lt 0 ]; then echo “RI Count is less than EC2 Count in $line Instance Type” grep -v “$line” reserved_instances_count.csv > reserved_instances_count_updated.csv mv reserved_instances_count_updated.csv reserved_instances_count.csv echo “$reserved_instance” awk -v line=”$line” -v reserved_instance=”$reserved_instance” ‘$1 == line {$2 -= reserved_instance}1’ ec2_instances_count.csv > ec2_instances_count_updated.csv mv ec2_instances_count_updated.csv ec2_instances_count.csv else echo “RI Count is Equal than EC2 Count in $line Instance Type” grep -v “$line” ec2_instances_count.csv > ec2_instances_count_updated.csv mv ec2_instances_count_updated.csv ec2_instances_count.csv grep -v “$line” reserved_instances_count.csv > reserved_instances_count_updated.csv mv reserved_instances_count_updated.csv reserved_instances_count.csv fi done < “$file_path” awk ‘{ if ($0 ~ /4xlarge/) { sub(/4xlarge/, “large ” $2*8, $0); } }1’ reserved_instances_count.csv | awk ‘{print $1, $2}’ > temp.txt && mv temp.txt reserved_instances_count.csv awk ‘{ if ($0 ~ /2xlarge/) { sub(/2xlarge/, “large ” $2*4, $0); } }1’ reserved_instances_count.csv | awk ‘{print $1, $2}’ > temp.txt && mv temp.txt reserved_instances_count.csv awk ‘{ if ($0 ~ /xlarge/) { sub(/xlarge/, “large ” $2*2, $0); } }1’ reserved_instances_count.csv | awk ‘{print $1, $2}’ > temp.txt && mv temp.txt reserved_instances_count.csv awk ‘{ if ($0 ~ /4xlarge/) { sub(/4xlarge/, “large ” $2*8, $0); } }1’ ec2_instances_count.csv | awk ‘{print $1, $2}’ > temp.txt && mv temp.txt ec2_instances_count.csv awk ‘{ if ($0 ~ /2xlarge/) { sub(/2xlarge/, “large ” $2*4, $0); } }1’ ec2_instances_count.csv | awk ‘{print $1, $2}’ > temp.txt && mv temp.txt ec2_instances_count.csv awk ‘{ if ($0 ~ /xlarge/) { sub(/xlarge/, “large ” $2*2, $0); } }1’ ec2_instances_count.csv | awk ‘{print $1, $2}’ > temp.txt && mv temp.txt ec2_instances_count.csv python3 ri_list_reserved_instances_count.py | sort | sed ‘s/\t/ /g’ > temp.txt && mv temp.txt reserved_instances_count.csv python3 ri_list_ec2_instances_count.py | sort | sed ‘s/\t/ /g’ > temp.txt && mv temp.txt ec2_instances_count.csv awk ‘{print $1}’ reserved_instances_count.csv > reserved_instances_type.csv file_path=”reserved_instances_type.csv” # Use a for loop to read and print each line while IFS= read -r line; do reserved_instance=$(cat reserved_instances_count.csv | grep “$line” | awk ‘{print $2}’) ec2_instance=$(cat ec2_instances_count.csv | grep “$line” | awk ‘{print $2}’) if [ -z “$ec2_instance” ]; then ec2_instance=0 fi result=$(($reserved_instance – $ec2_instance)) if [ $result -gt 0 ]; then echo “RI Count is Greater than EC2 Count in $line Instance Type” grep -v “$line” ec2_instances_count.csv > ec2_instances_count_updated.csv mv ec2_instances_count_updated.csv ec2_instances_count.csv echo “$ec2_instance” awk -v line=”$line” -v ec2_instance=”$ec2_instance” ‘$1 == line {$2 -= ec2_instance}1’ reserved_instances_count.csv > reserved_instances_count_updated.csv mv reserved_instances_count_updated.csv reserved_instances_count.csv elif [ $result -lt 0 ]; then echo “RI Count is less than EC2 Count in $line Instance Type” grep -v “$line” reserved_instances_count.csv > reserved_instances_count_updated.csv mv reserved_instances_count_updated.csv reserved_instances_count.csv echo “$reserved_instance” awk -v line=”$line” -v reserved_instance=”$reserved_instance” ‘$1 == line {$2 -= reserved_instance}1’ ec2_instances_count.csv > ec2_instances_count_updated.csv mv ec2_instances_count_updated.csv ec2_instances_count.csv else echo “RI Count is Equal than EC2 Count in $line Instance Type” grep -v “$line” ec2_instances_count.csv > ec2_instances_count_updated.csv mv ec2_instances_count_updated.csv ec2_instances_count.csv grep -v “$line” reserved_instances_count.csv > reserved_instances_count_updated.csv mv reserved_instances_count_updated.csv reserved_instances_count.csv fi done < “$file_path” |
This script focuses on Reserved Instances (RIs) management and EC2 instance optimisation for cost savings in an AWS environment. The script compares the number of EC2 instances running across different types with the Reserved Instances (RI) purchased, identifies discrepancies, and adjusts calculations for potential over/underutilization of RIs. It also checks specific instance types, ignores certain instances (like ECS or Spot), and outputs a comparison of EC2 vs RI usage.
Here’s a summary of what the script does:
- Generate a CSV of Running EC2 Instances:
- The script first generates a CSV (ec2_instances_main_account.csv) that lists all running EC2 instances in the main AWS account along with their names and instance types.
- Command Used: aws ec2 describe-instances
- The instances are filtered based on the instance state running and the output includes instance names and types, which are then sorted and made unique to avoid duplicates.
- Ignore Certain Instances (ECS, Spot Instances):
- Another file (ec2_instances_ignore.csv) contains the list of instance types to ignore (like ECS or Spot instances).
- The script checks the running instances list and adds any ECS or Spot instance types that are not already in the ignore list to the ignore list, avoiding duplicates.
- Filter Ignored Instances:
- The script filters out any instance types that are listed in the ignore list from the main EC2 instances CSV (ec2_instances_main_account.csv) so that only the relevant EC2 instances remain.
- Count Instance Types:
- The script counts the number of instances by type and outputs the count to a file (ec2_instances_count.csv).
- Reserved Instances (RI) Count:
- The script executes a Python script (ri_list.py) that outputs a list of Reserved Instances (RI) by type and the count of each RI type. This is stored in reserved_instances_count.csv.
- Similarly, it extracts the RI types into reserved_instances_type.csv for further processing.
- Compare RI and EC2 Instance Counts:
- The script loops through each instance type, comparing the number of running EC2 instances (ec2_instances_count.csv) with the Reserved Instances (RI) (reserved_instances_count.csv).
- Based on the comparison:
- If the RI count is greater than the number of EC2 instances for that type, it removes the excess RIs.
- If the RI count is less, it removes the excess EC2 instances from the list to balance the count.
- If the counts are equal, no action is taken.
- Handle Different Instance Sizes:
- The script then processes instance sizes like xlarge, 2xlarge, and 4xlarge and normalizes them by converting them to large instances.
- This is done to better track the RI usage against EC2 usage since AWS allows RIs to cover instances of different sizes (e.g., one 4xlarge instance can be equal to eight large instances).
- Finally:
- After adjusting the sizes and normalizing the counts, the script runs the Python scripts (ri_list_reserved_instances_count.py and ri_list_ec2_instances_count.py) again to ensure that the final counts of EC2 instances and RIs are aligned.
- Any remaining discrepancies are handled and the script ensures that the final count reflects the actual usage.
This process has enabled us to right-size our instances, ensuring that we aren’t wasting resources by over-provisioning or missing out on potential savings.
The use of RIs and Savings plan across all of our AWS accounts helped us save on 30% of our EC2, RDS, EMR and Sagemaker costs.
A Real-World Challenge: Lack of Visibility in RI Usage
We had an instance where the lack of visibility in RI utilization led us to overcommit on RIs, particularly in our APAC region, causing unnecessary expenditures. It took us weeks of manual labor to figure out which services were consuming the RIs. Post the introduction of the script, this process is now automated, saving both time and money.
2. RDS, S3, WAF, and CloudFront Cost optimisation
S3 Cost optimisation: Managing the Storage Beast
The cost of S3 storage had been steadily increasing, and we realised we were storing a lot of unnecessary objects. After some analysis, we noticed:
- Many files were rarely or never accessed.
- Old snapshots were lingering, taking up valuable space.
- DTO (Data Transfer Out) costs were also climbing due to increased object access.
Our solution? Implement S3 Lifecycle Policies and Athena-based object analysis. We used access logs to identify frequently accessed objects and moved older, unused files to Glacier or deleted them altogether.
Here’s an Athena query that we used to analyse S3 access patterns:
| sql SELECT key, COUNT(*) AS access_count FROM s3_access_logs WHERE event_time > date_sub(‘day’, 30, current_date) GROUP BY key ORDER BY access_count DESC; |
S3 DTO Cost Savings with Athena
We integrated AWS Athena to analyse S3 access logs, tracking Data Transfer Out (DTO) by object and folder. By pinpointing frequently accessed objects, we were able to determine which could be archived, reducing our DTO costs by 15%.
CloudFront and WAF Cost optimisation
To mitigate WAF and CloudFront costs, we began using CloudFront to cache content and WAF on Shield to manage incoming traffic. This combination not only increased security but also reduced DTO costs.
Real-World Case: Surging Costs Due to Poor Caching Configurations
In July, we encountered a major spike in our CloudFront DTO costs due to poorly configured cache rules. Our Shopify integration was causing multiple API calls for the same data, leading to increased DTO costs. After fixing the caching issue, we saw immediate cost reductions, bringing our DTO costs down by more than 75%.
3. EC2 Volume and Data Transfer optimisation
Volume Snapshot Costs
For EC2 volumes, we realised that while our GP2 to GP3 migrations were reducing storage costs, we were being hit hard by volume snapshot costs. Our snapshotting policies were outdated, leading to unnecessary backups and increased costs.
By implementing lifecycle policies to automatically delete old snapshots and optimising our snapshot schedule, we were able to cut down our costs by 25%.
Inter-AZ Data Transfer Costs (DTO)
One major surprise came from inter-AZ data transfer costs. We noticed that developers were sometimes using services across AZs without realizing the implications. This was especially true for Redis—since it’s so fast, developers weren’t aware of how much data they were transferring.
Real-World Case: Redis Misconfiguration
One afternoon, we suddenly saw a spike in inter-AZ DTO costs related to Redis. Upon investigation, we found that developers had unknowingly started using Redis across availability zones. This mistake cost us a 10-20% increase in DTO costs. After reconfiguring the services to stay within a single AZ, we were able to reduce our costs drastically.
4. CloudWatch and Log Group optimisation
CloudWatch logs were another cost center that needed optimisation. We were storing logs longer than necessary, leading to unnecessary egress charges and log storage costs.
Our Strategy:
- Unused Log Group Identification: We analysed which log groups were no longer in use or required long-term storage.
- Log Retention Policy: We introduced log retention policies to automatically delete logs after a certain period, ensuring we didn’t store unnecessary data.
- Egress Cost Management: We also identified certain logs that were incurring egress costs due to being stored in S3. After careful analysis, we decided to limit the retention period for logs that were rarely accessed, reducing both S3 and egress costs.
5. WAF optimisation
WAF optimisation focused on staying within WCU (WebACL Capacity Unit) limits. We took a multi-step approach:
- Consolidating rules: Merging redundant rules to reduce WCU.
- optimising rule execution order: Ensuring that the most efficient rules ran first, reducing unnecessary traffic through the WAF.
- Integrating CloudFront: We also offloaded some traffic to CloudFront to reduce the load on WAF.
This reduced our overall WAF costs by 15-20%, while still maintaining high security standards.
6. Leveraging Spot Instances
One of our most successful cost-saving strategies has been leveraging spot instances. By migrating 75-80% of our workloads to spot instances, we were able to cut costs significantly. Spot instances saved us up to 80% on certain workloads, allowing us to reinvest in other areas like security and monitoring.
However, spot instances come with their own set of challenges, interruptions being the primary one. To mitigate this, we implemented automated failover mechanisms that seamlessly moved workloads to on-demand instances if spot instances were interrupted.
7. Real-Time Monitoring and Alerting with ELK and Grafana
Monitoring and alerting are critical when optimising cloud costs. We implemented ELK (Elasticsearch, Logstash, Kibana) to monitor our GCP and AWS costs in real-time. Grafana dashboards were set up to track key metrics like DTO, EC2 usage, spot instance interruptions, and WAF costs. This provided a centralized view of our cost metrics, allowing us to take swift action when anomalies were detected.
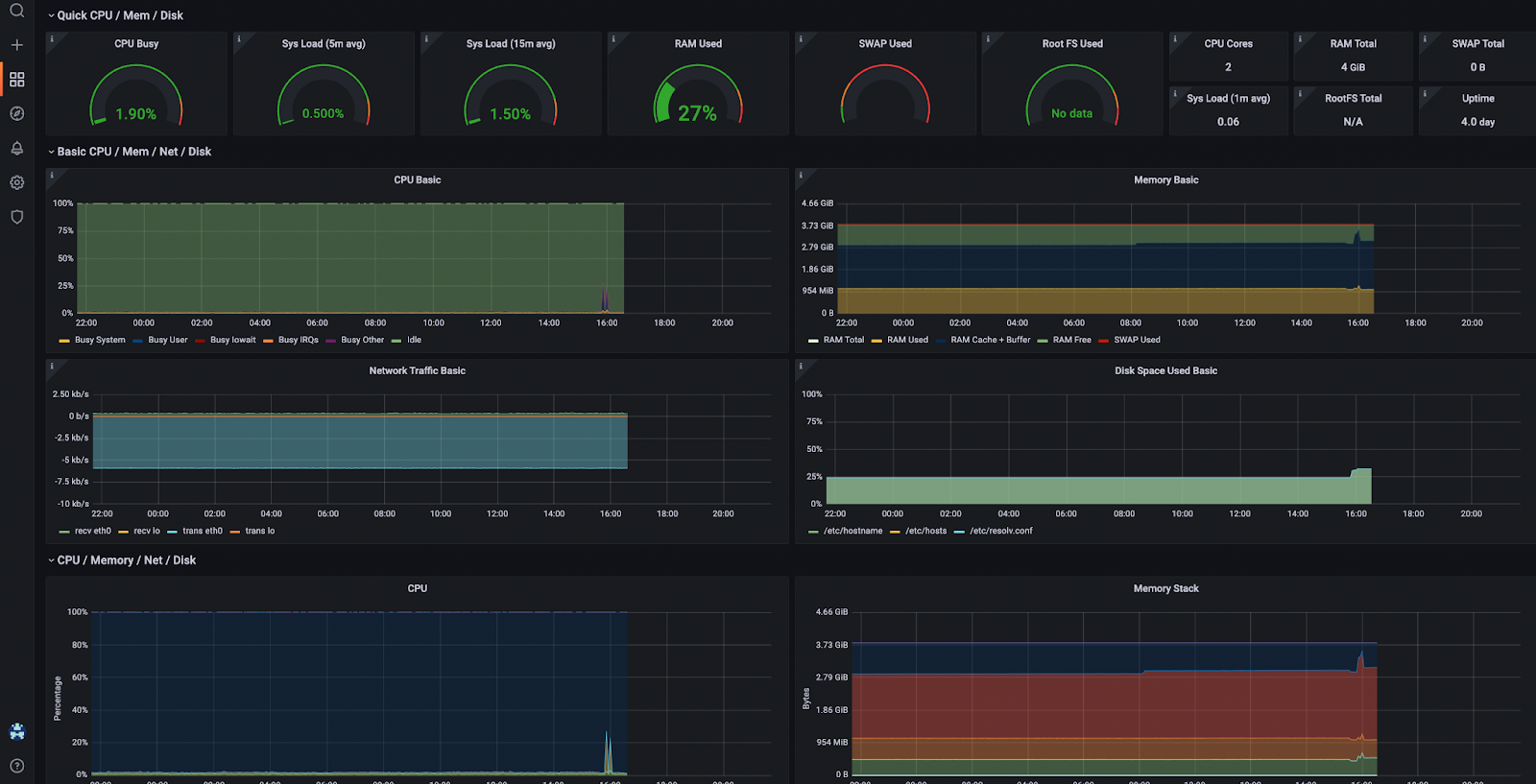
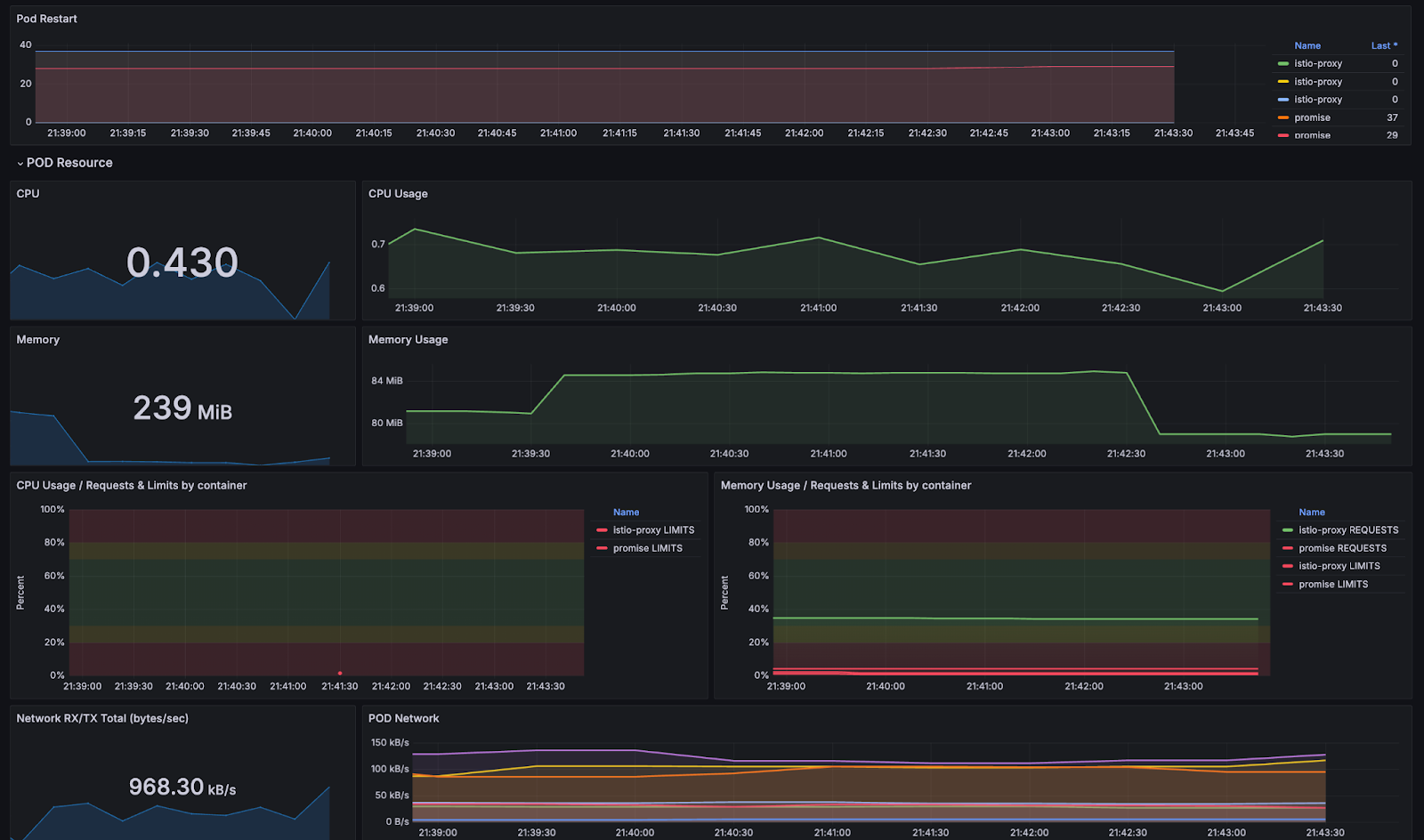
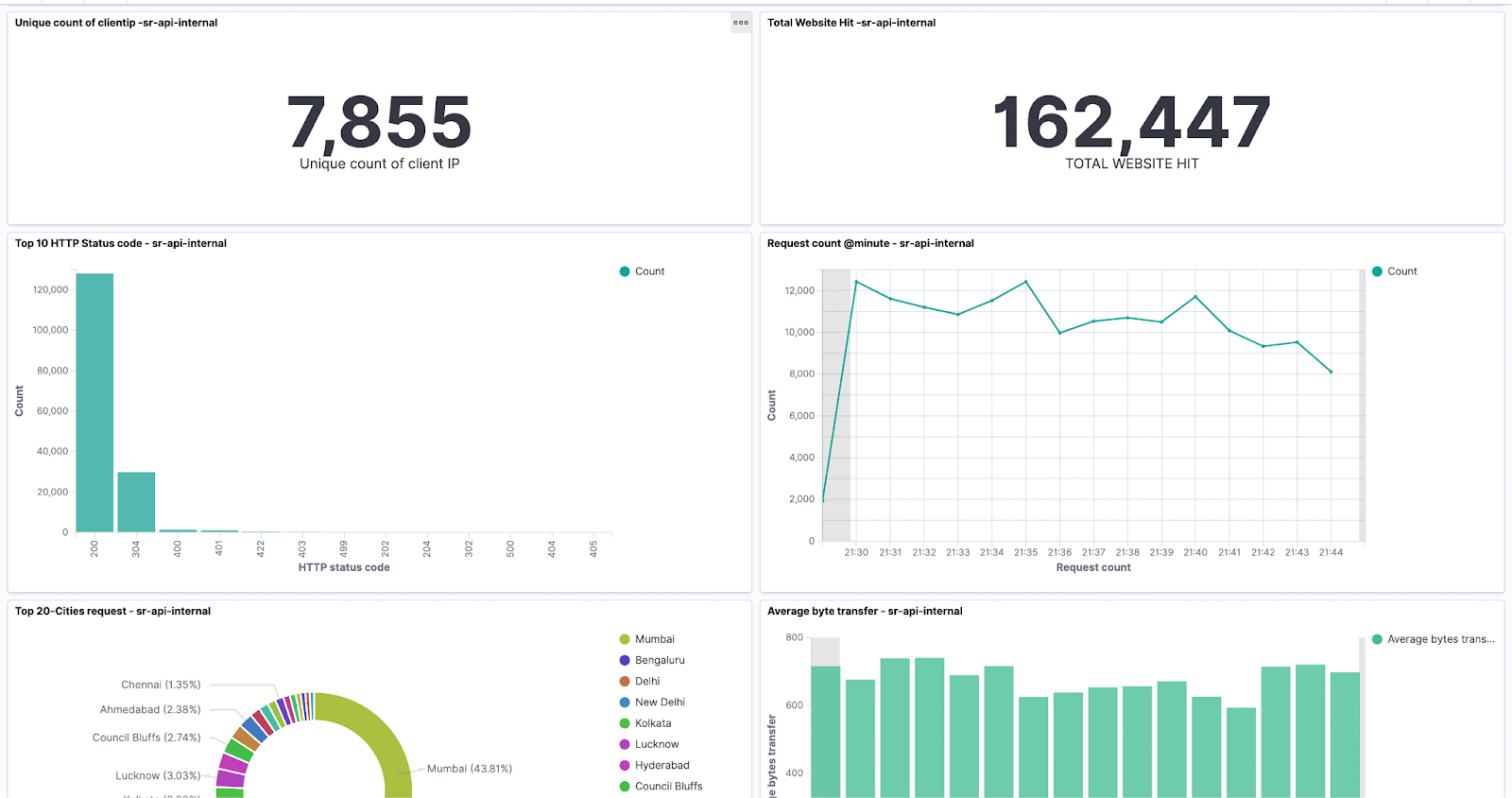
8. Real-World Successes: Achieving Meaningful Cost Savings
At Shiprocket, our cost optimisation efforts have resulted in significant savings across multiple areas:
- S3 cost reduction: By optimising object storage and implementing lifecycle policies, we reduced costs by 20%.
- EC2 and DTO optimisation: Redis and EC2 misconfigurations that caused spikes in DTO were identified and corrected, saving thousands of dollars in unexpected charges.
- Spot instance savings: Migrating the majority of our workloads to spot instances has resulted in savings of up to 80% for those workloads.
- WAF and CloudFront: By optimising WAF rules and using CloudFront for caching, we reduced WAF costs by 20%.
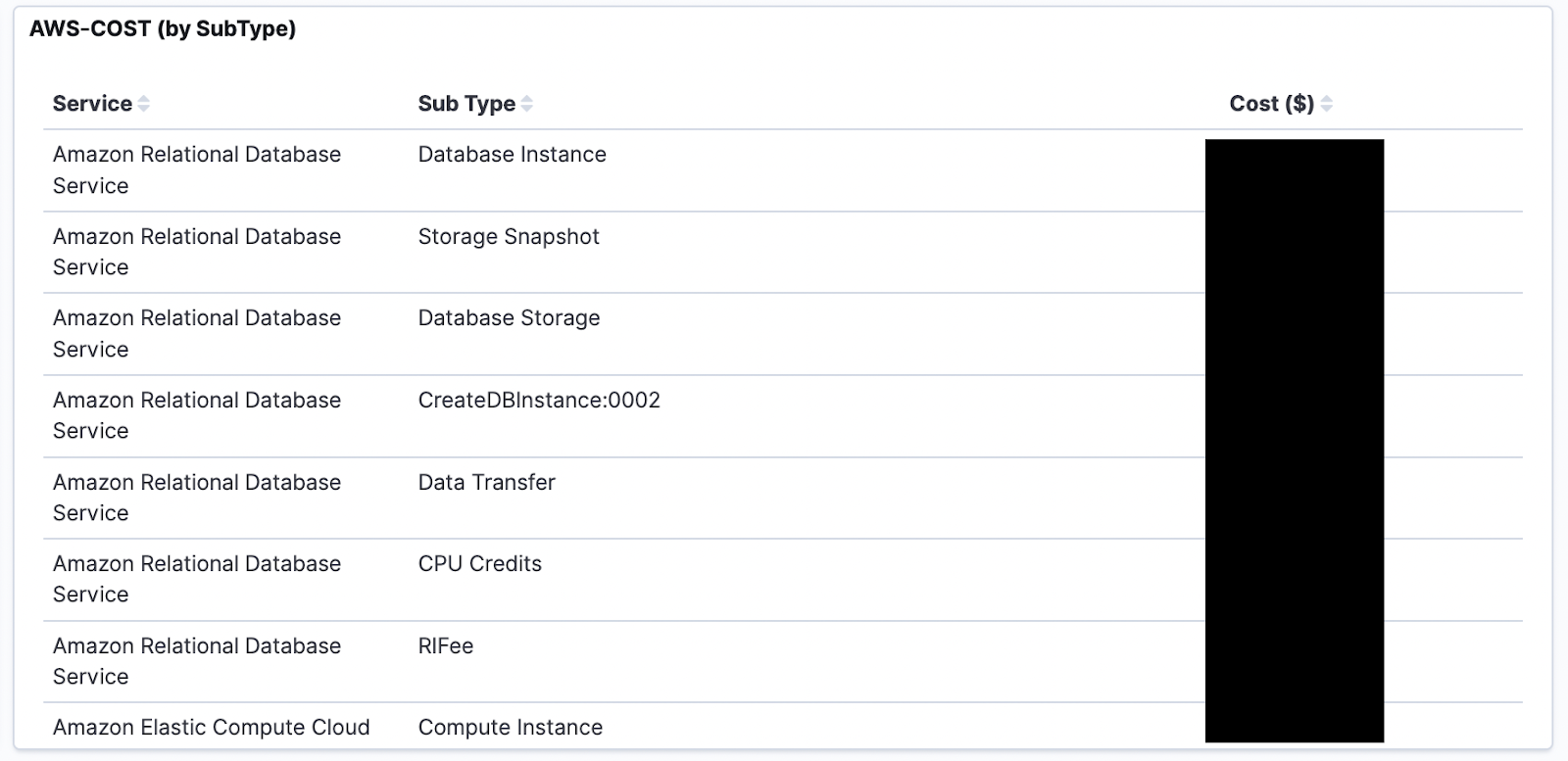
Below are some of our cost dashboards that we maintain as part of healthy FinOps practices:
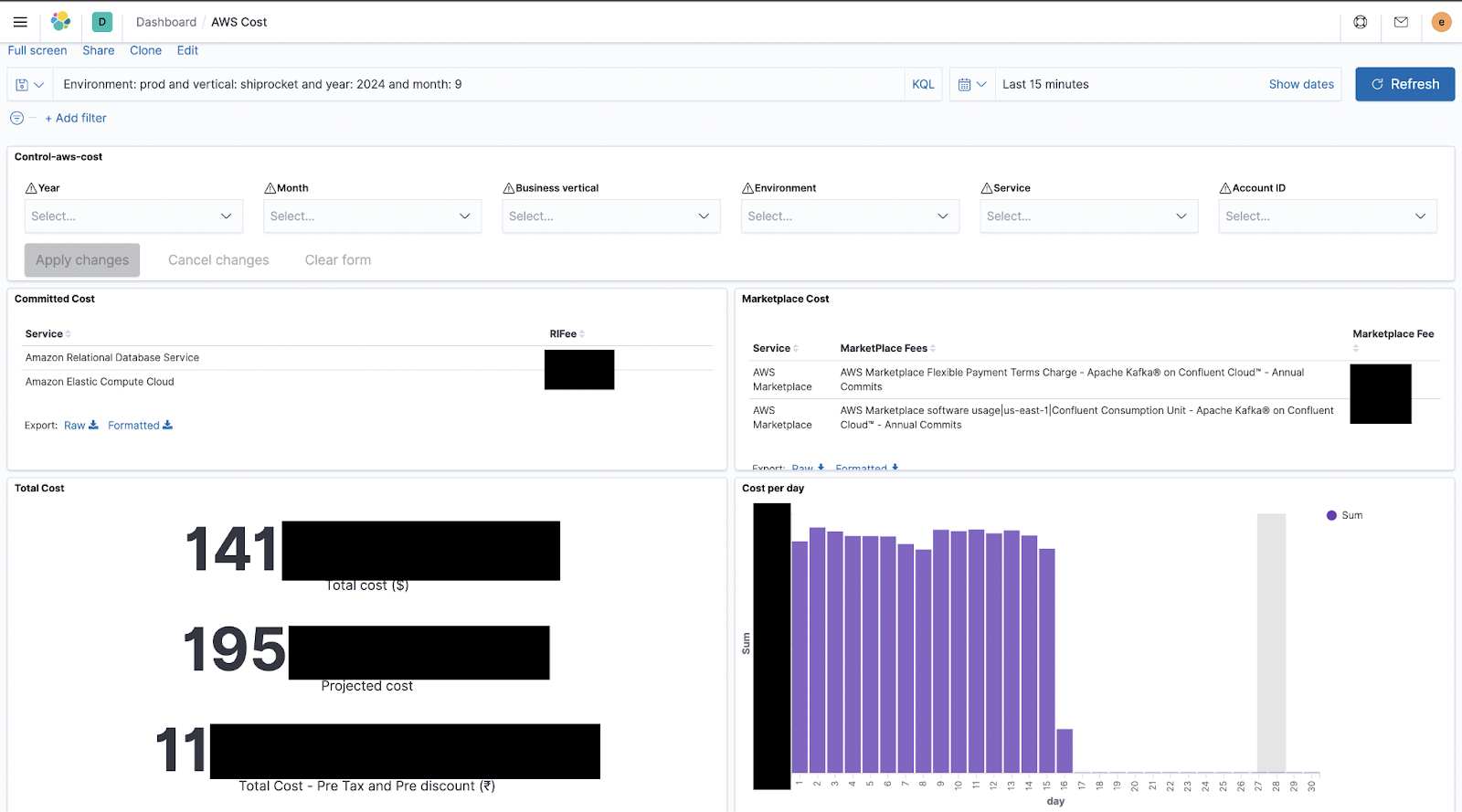

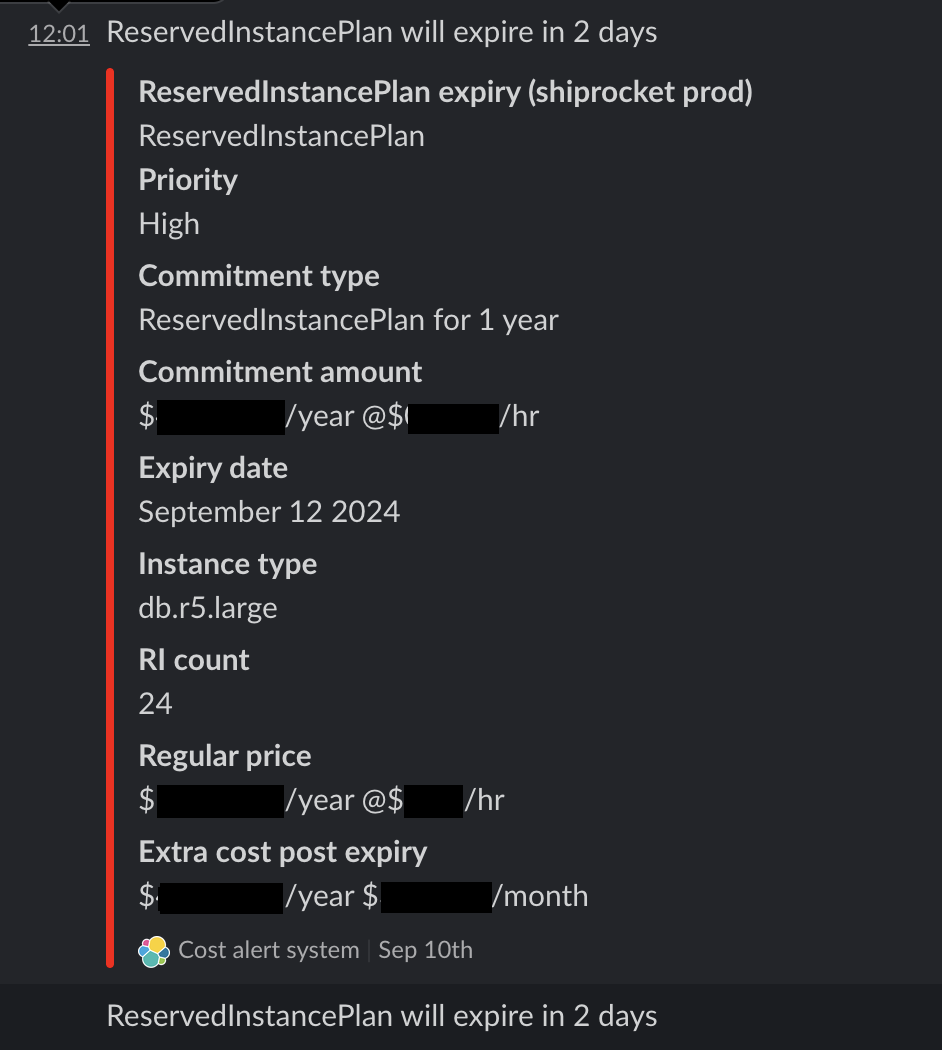
And this is how we track cost alerts on our slack platform:
9. GP2 vs GP3 for EBS Volumes: optimising Costs
At Shiprocket, we identified a potential cost-saving opportunity by comparing GP2 and GP3 EBS volumes. While GP3 volumes generally provide better performance for high IOPS workloads at a lower cost, there are certain scenarios where sticking to GP2 can actually lead to cost savings.
- Lower IOPS Requirements: For instances where the IOPS (Input/Output Operations Per Second) requirements are relatively low (below 3000), GP2 volumes can offer a cost advantage. GP3 is typically beneficial when you need a higher baseline of IOPS, but if the workloads don’t require it, GP2 offers a balanced, performance-per-cost ratio.
- Burstable Performance: With GP2, we noticed that burstable IOPS were enough to cover some of our sporadic workloads that didn’t need sustained high throughput, meaning we could avoid paying for GP3’s dedicated IOPS.
- Use Case optimisation: For smaller disk sizes (below 1 TB), GP2 has been proven to be cost-effective, especially for staging or non-production environments where we don’t need consistent high throughput. For production workloads with larger disk sizes and more intensive IOPS requirements, we shifted to GP3 to take advantage of lower prices for increased performance.
Conclusion: By implementing a hybrid approach between GP2 and GP3 based on workload requirements, we have achieved a cost reduction of approximately 15-20% on storage, while ensuring that we meet performance demands for high-traffic services.
10. Cost Reduction by Using NAT Instances Instead of NAT Gateways
Another key learning in our cost optimisation strategy came from evaluating the cost efficiency between NAT Gateways and NAT Instances. NAT Gateways are fully managed services, which offer simplicity but at a higher cost, especially with large data transfer volumes.
- Cost Comparison: NAT Gateway charges involve both hourly rates and per GB data transfer costs, which can escalate quickly for high-volume environments. NAT Instances, on the other hand, offer more flexibility in terms of instance type, enabling us to scale up or down based on actual traffic.
- Scalability and Flexibility: In several of our environments, particularly in staging and testing, we switched to using NAT Instances. By choosing smaller EC2 instances for lower traffic regions and auto-scaling to meet fluctuating demands, we were able to cut down on costs significantly. We implemented monitoring scripts to automatically shut down instances during periods of low traffic, such as off-peak hours.
- Savings Breakdown: By replacing NAT Gateways with NAT Instances in non-critical environments, we saved roughly 40-60% on networking costs. For production environments with consistently high traffic, we continue to use NAT Gateways for reliability and managed services benefits.
11. Avoiding Cost with S3 Delete Markers: A 20L Lesson
In the past, we experienced a significant cost spike when handling S3 object deletions. A delete marker is created when an object is deleted from a versioned S3 bucket, but the object is not immediately removed. Over time, this led to the accumulation of unnecessary storage costs.
- The Issue: While we thought deleting objects from S3 would automatically free up space, in reality, the delete markers remained in the bucket, continuing to occupy space and contributing to growing storage costs. This issue went unnoticed until we incurred a staggering 20 lakh (₹2,000,000) expense in a single quarter.
- The Solution: After recognizing this, we implemented lifecycle policies to automatically remove delete markers and their corresponding objects after a set retention period. Additionally, we set up monitoring scripts to flag buckets with accumulating delete markers and generated alerts whenever the number of markers crossed a certain threshold.
- Result: Since implementing these policies and real-time alerts, we have managed to avoid recurring costs associated with delete markers and potentially saved thousands of dollars per quarter. This was a valuable learning experience for our entire team, and we now ensure delete markers are closely monitored to prevent another costly mistake.
An Overview of Shiprocket’s Cost Optimisation Journey
The journey of cost optimisation at Shiprocket has been one of continuous improvement, leveraging tools, automation, and a sharp focus on detail. Through a combination of real-time monitoring, spot instance utilization, and continuous evaluation of cloud resources, we’ve managed to drastically reduce our cloud expenditure while maintaining high levels of performance, availability, and security.
The Importance of Cross-Functional Collaboration
What truly stands out in our cost optimisation journey is the collaborative effort between multiple teams – from DevOps, Security, Infrastructure, and even Finance. At Shiprocket, we value cross-functional teamwork, and it was evident in the success of our cost-saving initiatives. While our DevOps team focused on optimising infrastructure, our Finance team helped identify areas of potential savings, and Security teams ensured that cost reduction didn’t compromise the safety and integrity of our infrastructure.
One notable example was the effort to clean up unused snapshots and AMIs. Initially, it seemed like a routine task, but with the help of Finance providing insights into where costs were spiking, the DevOps and Security teams worked together to automate the cleanup process in a way that both reduced costs and maintained compliance with our security policies.
Overcoming the Hurdles
The journey wasn’t without its challenges. One of the more complex problems we faced was dealing with Redis misconfigurations across availability zones, which led to a massive spike in costs. Redis, being incredibly fast, often masked the real data transfer rates until it was too late. However, after discovering this issue, we quickly implemented a policy where any significant changes to multi-AZ deployments required a thorough cost review before going live. This not only fixed the issue but also ensured that such problems wouldn’t happen again.
Similarly, while implementing WAF cost optimisation, we initially underestimated the traffic flowing through the WAF. A surge of bot traffic exposed weaknesses in our rule sets, which led to a massive increase in Web ACL capacity units (WCU) usage. This caught us off guard. But by reordering rules, consolidating similar ones, and offloading some traffic to CloudFront, we managed to reduce WAF costs without compromising security. This was a real learning experience for the entire team.
Lessons Learned from the Cost Optimisation Initiative
Through our efforts, we’ve learned some important lessons that shaped our approach to cost management:
- Automation is Key: Without automated tools to manage Reserved Instances (RIs), monitor Data Transfer Out (DTO), and clean up unused resources, cost control would have been nearly impossible. Automated scripts ensured we could identify and resolve cost inefficiencies quickly.
- Proactive Monitoring Saves Money: By leveraging tools like Grafana, ELK, and AWS CloudWatch and our own cost monitoring scripts, we’ve been able to proactively monitor usage trends and catch anomalies before they become costly issues. For example, real-time DTO monitoring helped us identify spikes in data transfer and allowed us to intervene in real-time.
- Cross-Functional Collaboration is Crucial: Our success hinged on collaboration across DevOps, Security, FinOps, NOC, and Development teams. Each team brought its own insights and expertise to the table, allowing us to identify areas of improvement that may have otherwise gone unnoticed.
- Continual Iteration: optimising cloud infrastructure isn’t a one-time event. It’s an ongoing process that requires constant vigilance and iteration. As new features roll out, workloads shift, and usage patterns change, we continuously review our cost optimisation strategies and adjust accordingly.
- Don’t Underestimate Small Costs: One of our biggest surprises was how quickly small, seemingly insignificant costs (like cloudwatch log retention or inter-AZ Redis usage) can snowball into thousands of dollars of unnecessary expenditure. Monitoring the minutiae has saved us tens of thousands in the long run.
What’s Next for Shiprocket?
While we’ve made significant strides in cost optimisation at Shiprocket, the journey is far from over. With new projects and technologies on the horizon, we’re constantly looking for ways to improve our infrastructure, increase efficiency, and reduce costs. Our work with partners like Builder.ai has been invaluable in optimising RI and Savings Plans, but there’s always room for more automation and fine-tuning.
One exciting area we’re exploring is the further implementation of Spot Instances for even more workloads. With 75-80% of our workloads already on spot instances, we’ve seen firsthand how much potential savings exist here. However, we’re working on improving automatic failover mechanisms to make spot instance interruptions even less impactful.
In the future, we plan to:
- Expand our use of GreenOps practices by tracking and optimising the environmental impact and the Carbon footprint (CO2 emissions) of our cloud infrastructure.
- Leverage AI-powered anomaly detection for cost optimisation, ensuring that we can predict spikes in cloud costs before they occur.
- Continue to refine our cross-functional collaboration approach, ensuring that every team has input into cost-saving initiatives.
Conclusion
Cost optimisation at Shiprocket has been a challenging yet rewarding endeavour. From managing Reserved Instances to ensuring WAF cost efficiency, we’ve tackled cloud costs from multiple angles. Our success has been driven by automation, proactive monitoring, and strong cross-team collaboration.
As we look toward the future, we remain committed to optimising every dollar spent in the cloud, while also maintaining the highest standards of performance, security, and reliability. This journey isn’t just about saving money — it’s about building a scalable and sustainable infrastructure that can support Shiprocket’s growth for years to come. As our head of technology says: “Every penny saved is a penny earned”.