
- 3 Key Components of Shiprocket-Omuni, Inventory Management
- Shiprocket’s solution for the current implementation:
- Deduplication
- FC Enable/Disable control and monitoring
- Config to handle only necessary EAN inventory push
- Automated EAN Cleanup to Improve Inventory Efficiency
- NSTS Dashboard
- Partial Failure Handling in Inventory Update
- Conclusion :
Effective inventory management is the backbone of a successful business, enabling brands to maintain a smooth flow of products. However, achieving a resilient inventory management system can be challenging with ever-changing market conditions, customer demands, and supply chain disruptions. At Shiprocket-Omuni, we understand these complexities and strive to provide innovative solutions that help businesses streamline their inventory operations. In this blog, we’ll explore the key strategies and best practices to build a resilient inventory management system that not only withstands disruptions but also adapts to new challenges.

3 Key Components of Shiprocket-Omuni, Inventory Management
At Shiprocket-Omuni, inventory management is broken down into three key components:
- Inbound
- Core IMS
- Outbound
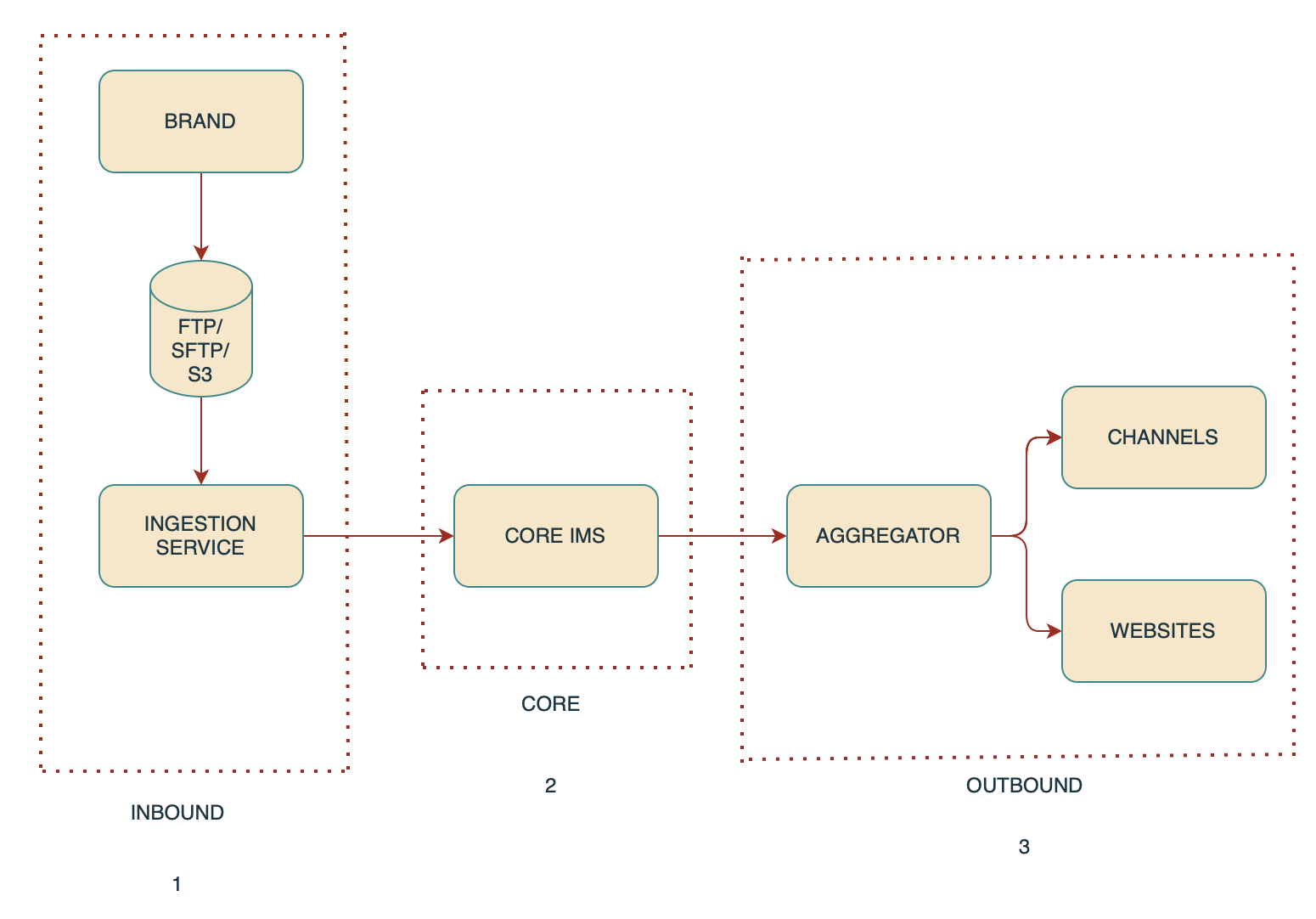
Inbound:
The brand uploads inventory files to external storage (FTP, SFTP, or S3). The Ingestion Service processes these files by reading and transforming the data, and then pushing it to the Core IMS Service for further handling.
Challenges faced in the inbound service
Previous implementation overview
Apache Camel plays a pivotal role in managing file-processing pipelines in our current system. Here’s an overview of how it works and the challenges we face:
- Route management
- Each application pod(in k8s) manages approximately 90 routes configured for various brands. There are around 30 brands for each brand 3 routes(1-article master, 1-delta, 1-reset).
- All routes are orchestrated using Camel Context for seamless integration.
- File polling and processing pipeline:
- Files are polled from external sources like SFTP/FTP/S3.
- Retrieved files are copied to a local mount storage, where a dedicated processor handles file processing.
- The entire process, from polling to processing, is driven by Apache Camel.
Drawbacks with the previous implementation
- Resource inefficiency: The presence of inactive threads results in wasted CPU cycles, even during periods of low activity.
- Load balancing issues: The lack of proper load balancing means that some pods may remain underutilised, while others are overwhelmed.
- Scalability bottlenecks: Vertical scaling of infrastructure increases costs and limits scalability, eventually leading to system resource exhaustion.
- Processing delays for large tenants:
- For smaller brands with ~20 stores, the system works efficiently.
- However, large tenants, which have thousands of stores, face significant delays:
- Full inventory synchronisation once daily takes around 2 hours.
- Frequent delta inventory updates are processed sequentially, further slowing down operations.
- Sequential processing limitations: The current design couples the poller and processor within the same service, forcing sequential file processing:
- This reduces throughput and increases the time required for large-scale operations.
- Scalability challenges:
- Thread utilisation:
- Each pod spawns 90 threads (one per route), many of which remain inactive but still consume system resources.
- These threads collectively utilise around 350mCPUs per pod.
- Load distribution: When new pods are spawned, load balancing across pods is inefficient, leading to unequal load distribution.
- Scaling issues: Scaling the infrastructure vertically becomes necessary to handle increased load, but this approach leads to CPU saturation at higher scales.
- Thread utilisation:
- No retry mechanism in case of failures: Any failure occurs while processing the file. Previously, the entire file is dropped from processing and the entire inventory will not be consumed which gives inventory mismatch between brands and channels/websites that turns to direct revenue loss.
Shiprocket’s solution for the current implementation:
Optimising inventory synchronisation with a decoupled architecture
To tackle the scalability and efficiency challenges in inventory synchronisation, the system has been restructured into a decoupled architecture. This approach separates the Poller Service and Consumer Service, enabling parallel processing and better resource utilisation. Here’s how the solution is designed:
Poller service
The Poller Service is tasked with monitoring file upload directories, generating metadata for detected changes, and pushing it to a message queue. The architecture is designed around a source folder, which contains subfolders for each brand. Each brand-specific folder further organizes files into three categories: article, delta, and reset.
When a file is added to any of these subfolders, the poller detects the change and processes the file as follows:
- Detection: New files added to {brandpath}/<DELTA/RESET/ARTICLEMASTER> are recognised by the poller.
Metadata Creation: The poller generates metadata with the following structure:
| { “fileDirPath”: “{entityPath}/<DELTA/RESET/ARTICLEMASTER>/inprogress/”, “fileName”: “<fileName>”, “fileCreatedAt”: “<timestamp>”, “fileType”: “<DELTA/RESET/ARTICLEMASTER>”, “fileSource”: “<SFTP/FTP/S3>”, “tenantId”: “<tenant_id>”, “entity”: “<entity>” } |
- File Handling: The file is moved to an inprogress folder located at {brandpath}/<DELTA/RESET/ARTICLEMASTER>/inprogress-<ipaddr>. After processing, the file in the {brandpath}/reset folder is deleted, eliminating the need for manual storage cleanup.
- Metadata Publishing: The generated metadata is pushed to a Kafka topic for further processing by the Consumer Service.
Scalability of the Poller Service
The poller system is designed to scale dynamically based on route configurations.
- Route Management: Each route is identified by a unique Route ID, stored in a central configuration store(mysql). For example:
| Route Id | Created At | Last Heartbeat at | Owner |
|---|---|---|---|
| MM | Timestamp | Timestamp | POD-IP |
| Bata | Timestamp | Timestamp | POD-IP |
| Khadims | Timestamp | Timestamp | POD-IP |
- Load Distribution: Each poller is configured to handle a maximum number of routes. If the total number of routes exceeds a poller’s capacity, additional pollers are deployed. For high availability (HA), multiple pollers can be deployed as backups.
- Ownership and Locking: Once a poller picks a route to monitor, it updates the configuration store with its IP and last updated timestamp to prevent duplicate processing by other pollers.
For example, if one poller can handle 20 routes and there are 40 routes in total, two pollers are required. For HA, four pollers can be deployed.
Consumer Service
The Consumer Service processes metadata published by the Poller Service and handles the corresponding files.
- File Retrieval: Using metadata, the consumer fetches files from FTP/SFTP/S3.
- Processing: Once processing is complete, the file is moved from {entitypath}/reset/inprogress to {entitypath}/reset/done.
- Error Handling: In case of an error, the consumer retries processing the file since messages are consumed from Kafka, ensuring fault tolerance.
Benefits of the Decoupled Architecture
- Improved Scalability: Dynamic scaling of pollers ensures that the system can handle increasing workloads efficiently.
- Enhanced Resource Utilization: Decoupling pollers and consumers allows independent scaling of each service based on demand.
- Fault Tolerance: Kafka-based message processing ensures reliable handling of failures and retries.
- Streamlined Storage Management: Automated cleanup of processed files eliminates the need for manual interventions.
Outbound
In Omuni, inventory updates must be synchronised with various channels and websites. The aggregator service manages inventory calculations based on EAN and publishes the calculated inventory to the respective channels configured for the brand.
Previously, integrating a new channel or website with Omuni required writing transformation code for the channel-specific POJOs and deploying it.
To simplify this process, we now use an open-source tool called FreeMarker Template. This eliminates the need to write any code or deploy changes. Instead, channels like Myntra, Flipkart, Meesho, Amazon, etc can be integrated seamlessly through configuration alone.
Deduplication
Problem statement:
In a distributed inventory management system, delays in processing messages from the queue can result in outdated inventory updates being sent to the marketplace. The challenge is compounded by marketplace rate-limit bottlenecks, especially during high-volume inventory transactions. For instance, consider a scenario where:
- Rate-Limit Impact: Marketplaces restrict the number of messages processed per second. If a large-scale inventory transaction involves 2 lac messages and the rate limit is 2 messages per second, it would take approximately 28 hours to sync the entire inventory.
- Inefficient Transaction Handling: For a specific EAN, multiple updates within a short time interval can lead to inefficiencies. Without a mechanism to capture the most recent change, the system may send redundant information to the marketplace.
These issues lead to:
- Inconsistent Inventory Updates: Outdated stock levels may cause overselling or order delays.
- Operational Delays: Rate limits significantly slow down synchronisation, impacting system responsiveness.
- Wasted Resources: Processing redundant messages for the same EAN wastes computational and network bandwidth.
A robust deduplication mechanism is essential to ensure that only the latest inventory updates, based on accurate timestamps, are processed and sent to the marketplace. This will help maintain data consistency, improve system efficiency, and reduce the impact of rate-limit bottlenecks.
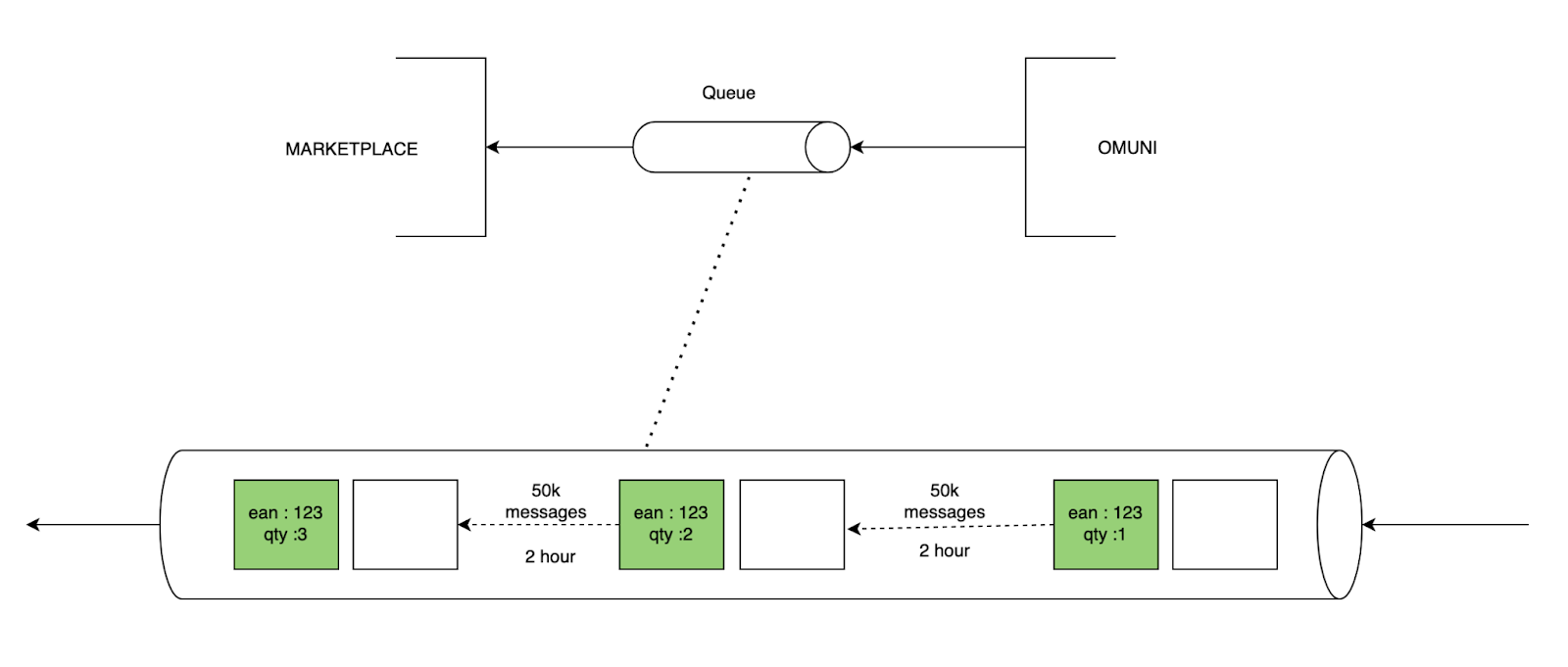
| Omuni | Marketplace | Possible outcome | ||
| Updated at 13:30 | { ean : 123 qty : 3} | Received at 13:30 | { ean : 123 qty : 3} | If Marketplace place 3 order which can be fulfilled |
| Updated at 13:40 | { ean : 123 qty : 2} | Received at 15:40 (2Hr Delay) | { ean : 123 qty : 2} | This inventory is already outdated, and at Omuni the inventory has been fully exhausted (quantity is 0), but this update has not yet reached the marketplace due to the lag, the marketplace is operating on stale inventory data. In this case, the marketplace is misinformed, showing a quantity of 2. This misinformation could result in the marketplace accepting orders for 2 units, which cannot be fulfilled because the actual inventory at Omuni is already depleted. |
| Updated at 14:05 | { ean : 123 qty : 1} | Received at 18:05 (2 Hr Delay) | { ean : 123 qty : 1} | |
Here, we can introduce a deduplication logic to prevent incorrect inventory updates to the marketplace caused by messaging queue lag. The approach involves using a distributed cache to store the latest quantity for each EAN, along with a timestamp and a flag called isProcessed.
Proposed Logic for Inventory Updates
Cache Update on New Messages
- Every inventory update message pushed to the queue will include a timestamp and an isProcessed flag.
- When a message is processed:
- The distributed cache is updated with the latest quantity for the corresponding EAN only if the message’s timestamp is more recent than the current entry in the cache.
- The isProcessed flag is set to true for that EAN, indicating that the message has been successfully processed.
Handling Delayed Messages
- If a message in the queue has an older timestamp and the isProcessed flag for that EAN is true, the system will discard the message, as it has already processed an earlier message with a more recent timestamp for that EAN.
- If the message has a more recent timestamp, it will be processed, and the cache will be updated accordingly.
Example Scenario:
- Case: EAN 123
- An update message for EAN 123 is pushed to the queue with a timestamp T1. The cache is updated with the quantity from this message.
- Another update message for EAN 123 is delayed in the queue and arrives later with an older timestamp T0.
- While processing this delayed message:
- The system compares the message’s timestamp (T0) with the cache’s timestamp (T1).
- Since T0 < T1, the system retrieves the quantity from the cache (associated with T1) instead of using the outdated message.
- While processing this delayed message:
- If the isProcessed flag for EAN 123 is set to true, all subsequent messages for this EAN are discarded.
This approach ensures that only the latest and most accurate inventory updates are sent to the marketplace, minimizing the impact of queue delays.
Outcome:
Eliminates Outdated Updates: By processing only the latest inventory updates for each EAN based on timestamps, the marketplace always receives the most accurate stock levels.
Prevents Overselling: Ensures real-time alignment between Omuni’s actual inventory and the marketplace, avoiding overselling or order cancellations.
FC Enable/Disable control and monitoring
Problem Statement:
Previously, OMUNI allowed multiple fulfillment centers (FCs) to be enabled or disabled simultaneously. However, this approach has caused bottlenecks due to the marketplace’s rate-limiting configuration. For instance, if the marketplace allows only 2 messages per second and a single store has 1 lakh EANs (products), there is no restriction on the brand disabling multiple stores at once.
If the brand team disables 10 stores simultaneously, all EANs for these stores need their quantities updated to 0. Since OMUNI operates with marketplace- and tenant-specific queues, all inventory updates must sync with the marketplace.
Calculation:
- Total messages: 10 stores × 1 lakh EANs = 1,000,000 messages
- Rate limit: 2 messages per second
- Total time: Total Time = Total messages / Messages per second = 10,00,000 / 2= 500,000 seconds=500,000 / 3600 ≈ 138.89 hour
During this time, OMUNI would show the inventory as updated to zero, but the marketplace may still display positive inventory counts. This mismatch could lead to orders being placed that cannot be fulfilled, as the FC is disabled.
Shiprocket’s Solution:
To avoid this issue:
- Restrict simultaneous operations: Avoid allowing multiple stores to be enabled or disabled at the same time.
- Process sequentially: Implement a system to handle these operations one store at a time, scheduling subsequent stores at suitable intervals.
- Show progress and estimates: Display a progress indicator in the UI for ongoing operations (enable or disable) with an estimated completion time.
- Allow order acceptance during disable progress: If a store is in the process of being disabled, it should still accept orders if placed during this time.
This approach ensures smoother synchronisation with the marketplace and avoids fulfillment issues caused by inventory mismatches.
With the new approach, EANs for only one store are processed at a time, while other stores display an estimated completion time. During the disable process, stores will continue accepting orders to ensure uninterrupted operations, as shown in the diagram below.
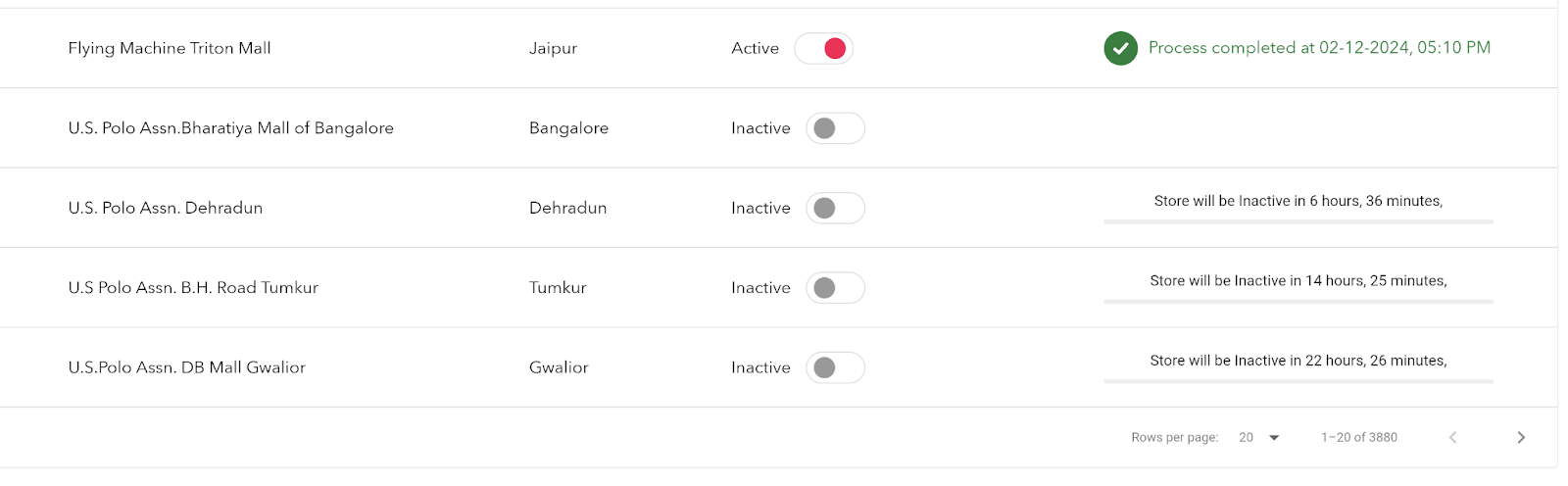
To implement this a Camunda workflow is integrated for every triggered event and remains active until all combinations of FC + SKU + Source (Marketplace) have been attempted at least once. The workflow monitors and manages the following parameters:
- Expected Turnaround Time:
- This represents the anticipated time required to complete the entire operation.
- The calculation is based on the number of SKUs for the specific FC + Source combination, with an added buffer.
- If the operation fails, the expected time is dynamically updated. However, if a predefined threshold is exceeded, the FC is forcefully disabled.
- Last Message:
- Refers to the final FC + SKU + Source combination that terminates the workflow.
- Failures:
- Tracks any communication failures between microservices.
- These failures are retried persistently until the operation succeeds.
By maintaining these parameters, the workflow ensures reliable execution and helps mitigate potential disruptions in the event processing pipeline.
Outcome
In conclusion, NSTS was significantly reduced as stores were disabled only after all inventory updates were successfully synced. Several infrastructure issues that caused failures in the system were identified and addressed. As a result, debugging time was reduced substantially, leading to improved system efficiency.
Config to handle only necessary EAN inventory push
Problem Statement
Currently, many SKUs in the fashion brand’s system are outdated and no longer relevant. These outdated SKUs should be flagged by the brand and removed from the system, but this process has not been completed yet. We have observed that 60-90% of the SKUs are outdated and should not be a part of the current inventory activity. However, their presence significantly increases the time required for inventory synchronization.
Whenever one of the following events are triggered a stream of events are pushed to Marketplace (Ordering source) which syncs the inventory of SKUs.
- FC Enable/Disable : Sync the quantity of all SKUs for a particular FC.
- SKU enable/Disable : Sync the quantity of a particular SKU which can be present in multiple FCs
- Style enable/Disable : Sync the quantity of all SKUs linked with the style which can be present in multiple FCs.
The size of the stream of events can grow very large as multiple events can be triggered at once. In order to restrict the number of events, we need to filter out unnecessary events from the stream.
Solution
- POSITIVE PUSH + 3 Month 0: In the above method we assume that the ordering source was completely in sync before the new stream of events started. However, this might not always be true due to failure of previous event failures. So in order to handle this, we can also choose those combinations that have 0 inventory but are no more than 3 months old. Here we assume that inventory updates generally happen on the recent SKUs and old SKUs can be discarded.
- POSITIVE PUSH : When an enable event is triggered, the exact quantity present needs to be synced with ordering sources. Before the sync operation starts all FC + SKU combinations will have 0 inventory present in ordering Sources. While choosing which FC + SKU combinations need to be synced, we can ignore the combination which has 0 inventory as those are not changing.
- FULL PUSH : Here all FC + SKU combinations are considered.
Outcome
POSITIVE PUSH + 3 Month 0 proved to eliminate most of the inventory sync issues. It also reduced the size of the sync stream by 80 percent, hence reducing the load on the systems involved and helping in reduced sync time.
Automated EAN Cleanup to Improve Inventory Efficiency
Problem Statement:
Over time SKUs get delisted on ordering sources. Since they are not delisted in our system, they continue to take part in inventory push events. Also, new SKUs might take time to be listed on ordering sources. Whenever an inventory update for an unknown SKU is pushed to ordering sources, third-party APIs throw specific exceptions. This triggers a lot of unwanted retries and takes up the rate-limiting bandwidth.
Solution
Errors from Marketplace inventory update APIs can be segregated into 3 categories, Retryable, Non-retryable, and Listing Error.
- By default all errors are retryable.
- To identify non-retryable and listing errors a mapping of ordering sources to Error codes/descriptions are preconfigured. Events that fail with non-retryable errors are simply discarded and there is no specific handling of those events.
- For listing errors, we store the events and have a daily retry mechanism in place. These events are retried for 5 days and then if the same error occurs, the SKU is deleted from our system. These are also identified from a preconfigured list of Error codes/description
Outcome
Significant reduction in third-party API calls. Identification and elimination of unused SKUs from our system.
NSTS Dashboard
Problem Statement:
Orders that cannot be fulfilled and move to NSTS (Unfulfillable) status can fail for various reasons. Identifying the primary reason becomes increasingly challenging over time due to the dynamic nature of the data. In many cases, determining the exact cause after a delay is nearly impossible. To address this, it is essential to capture a snapshot of the data at the time of the failure. This snapshot will help pinpoint whether the issue originated from the marketplace or Omuni, enabling accurate and timely diagnosis.
Solution
The NSTS dashboard plays a crucial role in storing key statuses necessary for debugging NSTS issues. Whenever an order moves to NSTS, it is important to capture all relevant factors at the time of the event. Some of the key fields to capture include:
- EAN status
- FC status (enabled/disabled)
- Inventory levels
- Last pushed inventory to the marketplace, with timestamp
- Last response from the marketplace, with a timestamp
- Inventory topic lag
- Last successfully pushed quantity
- Last attempted pushed quantity
- Exceptions during sourcing
- Exceptions from multiple services, such as IMS and FCM
By analysing the above fields, we can identify the exact reasons in a short time. Proper actions can be taken once the reason is known.
This dashboard is integrated into ELK. Hence it is easier to download reports within any given time interval.
Outcome
Reduced debugging time and improved visibility. Resolved almost all issues, except those on the marketplace side.
Partial Failure Handling in Inventory Update
Problem Statement:
Marketplace APIs generally accept inventory updates EAN + FC updates in batches. However, it is not guaranteed that all the updates will succeed. The overall response is SUCCESS but there may be partial failures. For eg. out of 10 EAN + FC updates, 8 will succeed, and 2 might fail with reasons mentioned in the response body. These failed updates can either succeed on retry or never succeed at all. Hence there was a need to filter out the failed updates and process them as per the reason obtained in the response body.
Solution
A mapping of retryable and non-retryable failure reasons is preconfigured. After getting a response from Marketplace API, the failed updates are filtered out and then segregated into either Retryable failure or Non-retryable failure. Retryable failures are pushed to a retry queue and retried a limited number of times. The non-retryable failures are discarded.
Outcome
We saw a significant drop in inventory sync issues which reduced NSTS.
Conclusion :
Shiprocket Omuni IMS empowers brands to implement a more streamlined and reliable inventory management solution. It synchronizes inventory data across platforms like Amazon, Flipkart, and other e-commerce channels, eliminating discrepancies and ensuring real-time stock consistency. By addressing latency issues between Shiprocket Omuni and integrated channels, it significantly improves update frequency and system responsiveness. These optimisations enhance inventory control and enable brands to deliver a seamless and accurate customer experience across multiple marketplaces and brand websites.