
- The Challenge: Wrestling with Complex Reporting in Multi-Tenant Architecture
- Traditional Approach: The Tortoise in the Race for Insights
- Our Solution: The Shiprocket Dream Team
- Debezium: The Real-Time Data Whisperer
- Kafka: The High-Speed Data Highway
- AWS Lambda and EventBridge: The Serverless Orchestrators
- Amazon S3 and AWS Glue Data Catalog: The Storage and Organization Duo
- Amazon EMR: The Big Data Powerhouse
- Trino: The Lightning-Fast SQL Query Engine
- Metabase: The User-Friendly Reporting Tool
- Shiprocket’s New Data Pipeline: Turning Chaos into Clarity
- How Does This Business Architecture Benefit Shiprocket?
- Additional Optimizations: Shiprocket is always tweaking for Perfection
- Conclusion: Turning Data Overload into Competitive Advantage
Most of you know how Shiprocket offers top-notch logistics services, but did you know we are more than just a shipping provider? In recent years, Shiprocket has evolved into a full-fledged, end-to-end solution that meets all your eCommerce needs. With over 12+ powerful products—ranging from domestic and international shipping, B2B & bulk shipping, hyperlocal deliveries, warehousing solutions, and express 1-day/2-day delivery to omnichannel support, revenue-based financing, API marketplace, seamless checkout experiences, and AI-driven communication tools—Shiprocket is redefining the logistics, marketing, and warehousing landscape.
With a growing network of 2,50,000+ merchants, Shiprocket strives for greater heights every day. But with great growth comes great responsibility—and an avalanche of data. Every product we offer generates vast streams of information that must be filtered, sorted, and managed to generate meaningful insights.
It’s no small feat, but through advanced analytics, intelligent system architecture, and a dedicated tech team, we’ve mastered the art of transforming raw data into actionable insights, empowering our merchants to scale their businesses effortlessly. Want to know how we do it? Let’s take a deep dive into our tech stack and the innovative systems that keep Shiprocket running smoothly, day in and day out, despite the challenges.

The Challenge: Wrestling with Complex Reporting in Multi-Tenant Architecture
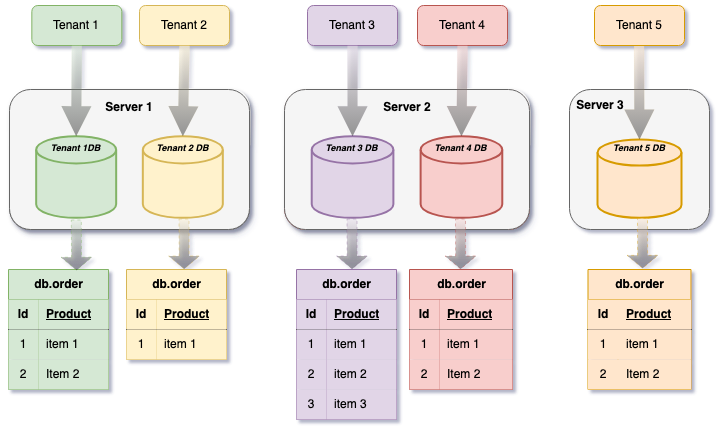
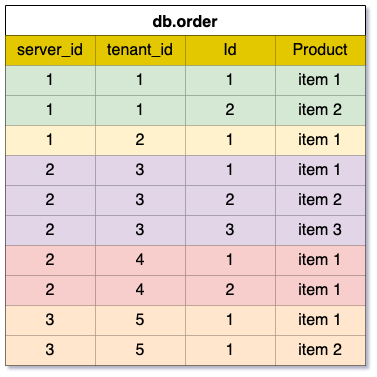
In a multi-tenant system, each client operates within their own database schema—a personal data bubble. While this setup was great for flexibility and security, managing more than 1,400 MySQL databases with 50,000+ tables became a monumental task for Shiprocket.
When we tried to pull insights from all these tenants, the decentralised data spiralled into a labyrinth. Real-time analytics turned into real-time headaches. The complexity skyrocketed as businesses demanded up-to-the-minute insights to make crucial decisions. Without an efficient system, we were left with data silos, delays, and a lot of frustration.
Traditional Approach: The Tortoise in the Race for Insights
The traditional way of handling this was to query each database individually and then combine the data at the application level. It was like putting together a jigsaw puzzle, with each piece as a different room. Here’s why this method didn’t cut it for us:
- Slow Insights: Querying over 1400+ databases was like running a never-ending marathon. By the time we got the insights, they were outdated, and critical business decisions were delayed.
- Inconsistent Data: Variations in schemas across tenants made the data as inconsistent as the weather, leading to unreliable metrics and reporting.
- High Resource Costs: The sheer computing power required for this was like using a flamethrower to light a candle—overkill and expensive. This approach led to operational delays, sky-high costs, and poor competitiveness for us.
Our Solution: The Shiprocket Dream Team
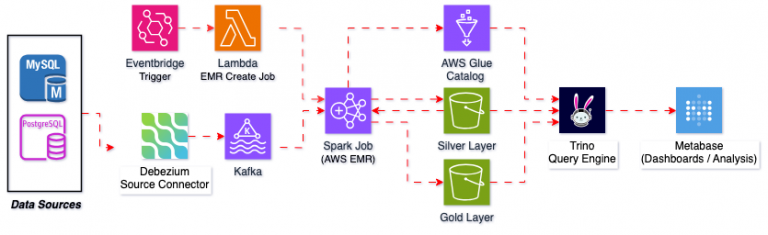
A great problem requires an even greater team, and that’s what we did. Tech-team, ASSEMBLE! And then, our efficient and tech-savvy experts took it upon themselves to devise a smart strategy that turns data into digestible chunks. With our dream team of experts, we built another dream team of technologies. Let’s introduce Shiprocket’s dream team of technologies: Debezium, Kafka, AWS Lambda, Amazon S3, Amazon EMR, AWS Glue Data Catalog, Trino, and Metabase. Together, these technologies simplified the complex process and created a real-time, efficient data pipeline for us.
Debezium: The Real-Time Data Whisperer
Debezium is an open-source Change Data Capture (CDC) tool that tracks every change in our MySQL databases in real-time without affecting performance. It’s like having a security camera on our data, capturing every insert, update, or delete.
Kafka: The High-Speed Data Highway
Kafka acts as the high-speed highway for the data coming our way. It ingests the change events from Debezium and streams them efficiently. Think of it as the Autobahn for all real-time data.
AWS Lambda and EventBridge: The Serverless Orchestrators
AWS Lambda processes the data on the fly as it streams through Kafka, performing real-time transformations without needing to manage servers. Amazon EventBridge routes events to the right places, ensuring the system runs smoothly.
Amazon S3 and AWS Glue Data Catalog: The Storage and Organization Duo
Amazon S3 is where all our processed data is stored. It is a scalable and durable solution for us. AWS Glue Data Catalog organizes the metadata and schema so that our data lake stays clean and organised, instead of being a confusing swamp of information.
Amazon EMR: The Big Data Powerhouse
Amazon EMR processes huge amounts of data using tools like Apache Spark. It reads the data from S3, processes it, and writes the results back, taking care of all the heavy lifting for us.
Trino: The Lightning-Fast SQL Query Engine
Trino (formerly PrestoSQL) is the tool for querying data stored in S3. It connects to the AWS Glue Data Catalog for schema info and allows our team to run fast SQL queries on large datasets with low latency.
Metabase: The User-Friendly Reporting Tool
Metabase sits on top of Trino, giving Shiprocket a simple, web-based interface for creating dashboards and reports. We don’t need to write SQL—we just point, click, and voila! We get the insights we need.
Shiprocket’s New Data Pipeline: Turning Chaos into Clarity
With Debezium capturing changes and Kafka streaming data, AWS services process and store it, ready for querying. Here’s how it all fits together:
- Data Capture: Debezium monitors our MySQL databases and captures every change in real-time.
- Data Streaming: Kafka ingests these changes and streams them to the system.
- Serverless Processing: AWS Lambda processes the streamed data, applying any needed transformations or enrichments.
- Event Management: Amazon EventBridge routes events to keep our data flowing efficiently.
- Data Storage: The processed data lands in Amazon S3, organized by AWS Glue.
- Data Processing: Amazon EMR processes large data sets using Spark.
- Interactive Querying: Trino runs queries directly on the S3 data using schemas from AWS Glue.
- Reporting: Metabase connects to Trino, giving our stakeholders real-time dashboards and reports.
How Does This Business Architecture Benefit Shiprocket?
- Real-Time Insights: We are now getting up-to-the-minute data allowing a faster decision-making.
- Scalability: The system scales automatically with our data and tenant growth, so all our worries related to the infrastructure are sorted.
- Consistent and Reliable Data: Centralised storage in S3 with proper cataloging ensures reliable and consistent data.
- Cost Efficiency: Serverless services like AWS Lambda keep our costs low. We pay only for what we use.
- User Empowerment: Metabase enables us to create reports and dashboards without the need for assistance from SQL or Python experts, significantly enhancing team productivity.
Additional Optimizations: Shiprocket is always tweaking for Perfection
- Caching with Trino: Caching frequent queries in Trino speeds up our response times and reduces the system load.
- Data Partitioning: We are able to easily partition our S3 data leading to significant improvements in query performance for large datasets.
- Schema Evolution: AWS Glue’s schema registry can manage changes in the data structure, preventing unexpected issues.
- Optimized Data Formats: Using columnar formats like Parquet or ORC has improved our performance and reduced storage costs.
- Critical Data Prioritization: Kafka has prioritised essential data streams like financial transactions, ensuring they’re always processed first.
Conclusion: Turning Data Overload into Competitive Advantage
By leveraging Debezium, Kafka, AWS services, Trino, and Metabase, Shiprocket has turned multi-tenant data chaos into a well-oiled machine. With our data architecture, we are able to:
- Stay Agile: Respond quickly to changes with real-time data at our fingertips.
- Scale Seamlessly: Grow without infrastructure headaches.
- Boost Efficiency: Reduce costs and improve performance.
- Empower Teams: Fueling our team’s success by giving them the necessary tools.
In today’s fast-paced digital world, efficiently handling massive amounts of data is key to staying competitive. At Shiprocket, we’ve turned data complexity into an advantage by streamlining the power of data to fuel growth, enhance customer experiences, and drive innovation. As we continue to scale and innovate, one thing remains constant: our dedication to helping businesses thrive with the smartest, most efficient solutions.