
The eCommerce industry thrives on speed, scalability, and reliability. Timely order processing, backed by real-time updates, is a crucial aspect of logistics that is non-negotiable for customers. At Shiprocket, where thousands of messages are processed every second, we needed a solution to handle heavy throughput without compromising performance. While initialising a new producer for every request was an option, it would have led to excessive resource consumption and scalability challenges. In our quest for the right solution, we found significant potential in Kafka producer pooling.
In this blog, we’ll explore why and how Kafka producer pooling became a go-to solution for Shiprocket, its implementation in Go using Goroutines and channels, and the measurable impact it can have on real-time messaging systems.

Kafka Producer Pooling: Why and When?
A Kafka producer is a network-intensive component that manages broker connections, buffers, and sends messages. It creates a new producer for each message is inefficient as it adds considerable overhead, especially in high-throughput applications. The benefits of producer pooling include:
- Reduced resource consumption: By reusing producers instead of creating new ones for each request.
- Performance improvement: Minimising producer initialisation overhead.
- Enhanced concurrency handling: Sharing a fixed number of producers across multiple requests for better resource management.
Using Goroutines and Channels for Producer Pooling
- Goroutines: Lightweight threads in Go that enable tasks to run concurrently.
- Channels: Safe communication mechanisms between goroutines.
- In producer pooling, channels manage a pool of pre-initialised Kafka producers, optimising message production.
Producer Pool Implementation
1. Defining the Producer Pool
- A buffered channel is used to store and manage Kafka producers.
- Example:

2. Initialising the Producer Pool
- Use a sync.Once block to ensure producer initialisation happens only once, even with multiple concurrent goroutines producing messages.
- Example:

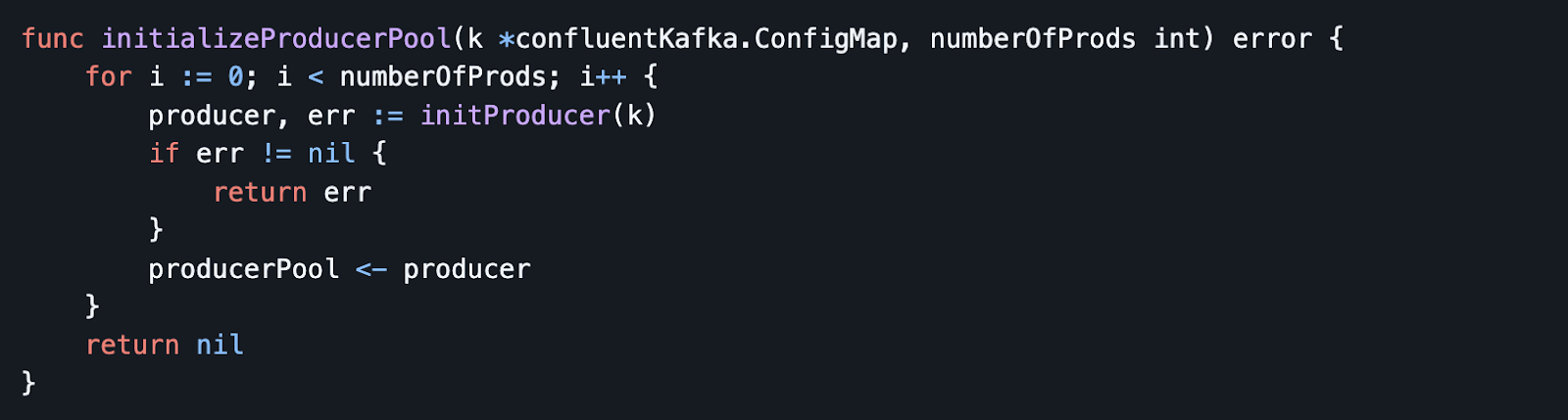
3. Producer Pool Initialisation Logic
- The initializeProducerPool function creates producers and adds them to the pool.
- Example:
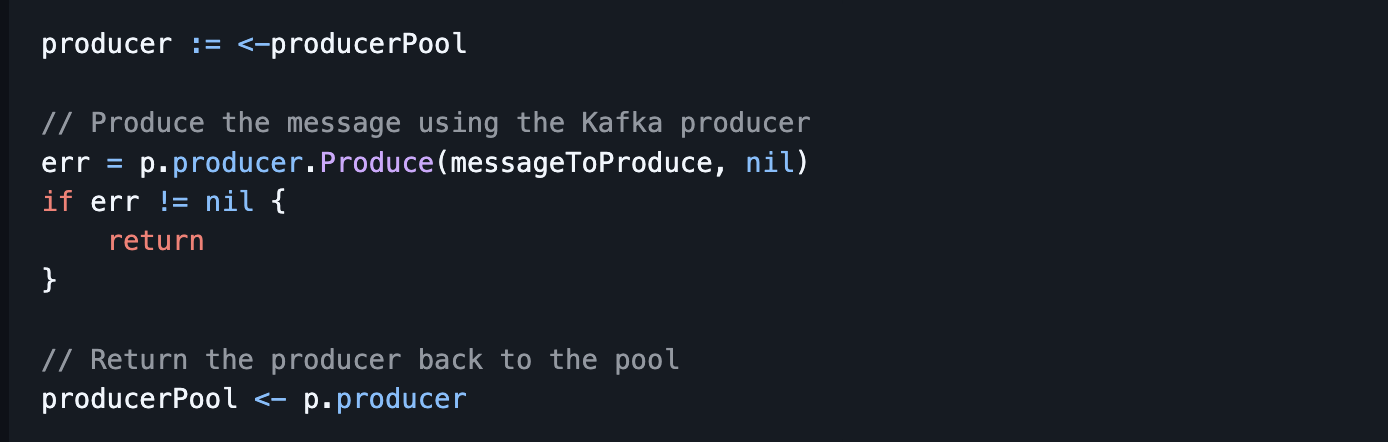
4. Using Producers from the Pool
- Producers are retrieved from the pool, used to send messages, and then returned to the pool.
- Example:
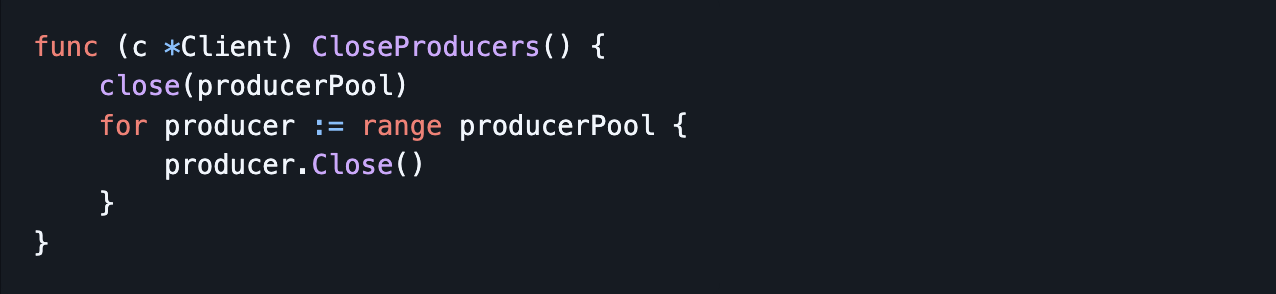
5. Graceful Shutdown
- Ensure all producers are properly closed during shutdown to prevent resource leaks.
- Example:
Concurrency and Goroutines
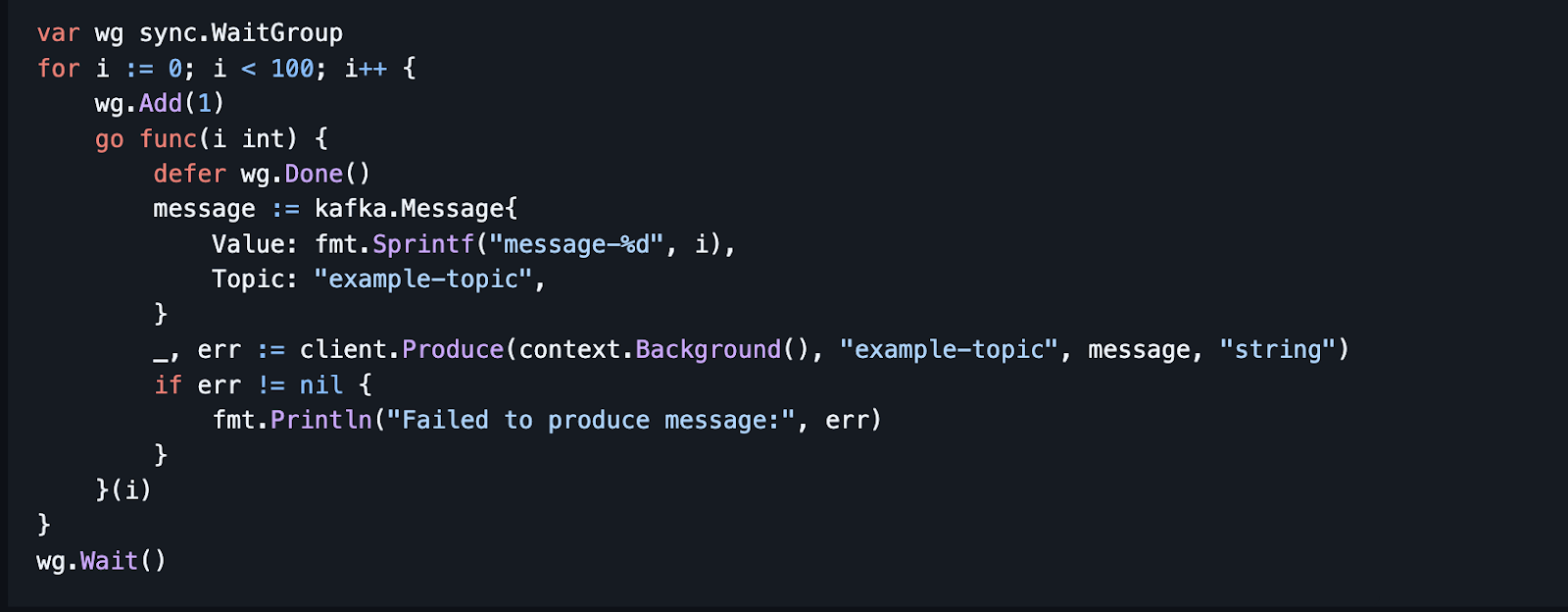
Example of Concurrent Message Production
- The following example uses a `sync.WaitGroup` to spawn multiple goroutines for concurrent message production.
- Example:
Key Takeaways
- Producer pooling: Reusing Kafka producers minimises overhead and enhances performance.
- Goroutines and channels: Effectively manage and share producers across concurrent requests by leveraging Go’s concurrency model.
- Graceful shutdown: Properly close and release producers to avoid resource leaks and ensure reliable message delivery.
Impact After Pool Implementation
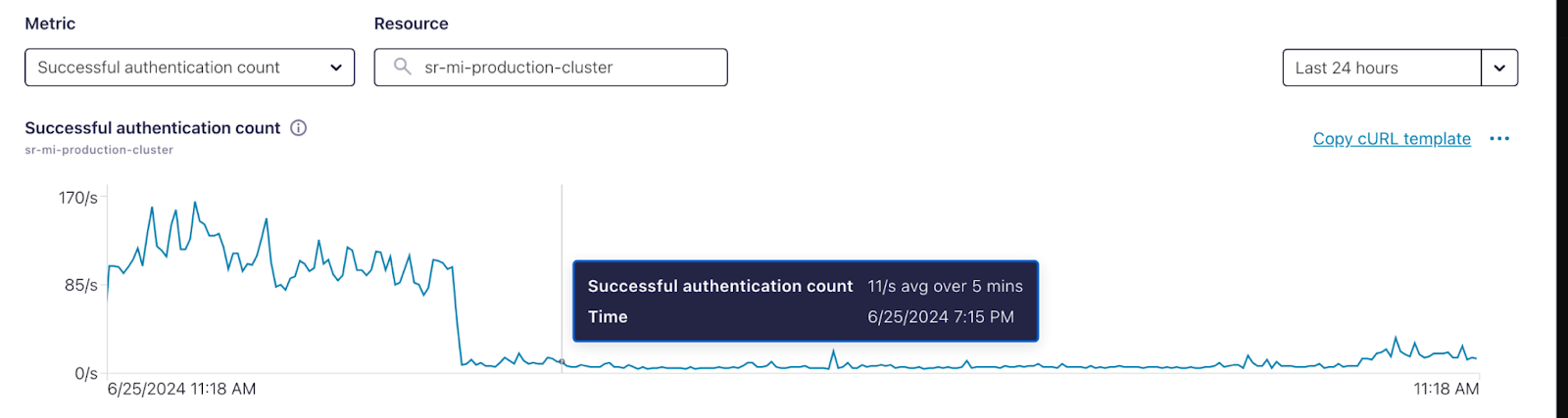
Conclusion
Kafka producer pooling in Go using goroutines and channels offered us a scalable, and high-performance approach for real-time messaging. This approach enhanced our performance, reducing resource usage, and is especially well-suited for high-throughput systems at Shiprocket.