Overview
In today’s data-driven world, organizations are constantly inundated with vast amounts of data. This data comes from various sources, both internal and external, and is generated at an unprecedented pace.
To harness the potential of this data, it’s essential to have a robust data storage and processing strategy in place. This is where a Data Lake comes into play.
What is a Data Lake?
A Data Lake is a centralized repository that allows organizations to store all their structured and unstructured data at any scale. Unlike traditional databases, Data Lakes provide a flexible and cost-effective solution for storing and processing large volumes of data. They store data in its raw, unaltered format, enabling data scientists, analysts, and other stakeholders to explore and analyze the data as needed.
Why Do We Need a Data Lake?
There are many benefits to using a Data Lake, including:
- Scalability: Data Lakes can scale horizontally to accommodate massive amounts of data. Whether you’re dealing with terabytes or petabytes of data, a Data Lake can handle it.
- Data Variety: Data Lakes can store various data types, including structured, semi-structured, and unstructured data. This flexibility allows organizations to capture data from diverse sources like IoT devices, social media, logs, and more.
- Cost-Efficiency: Data Lakes are typically built on cloud infrastructure, allowing organizations to pay only for the storage and computing resources they use. This eliminates the need for expensive upfront hardware investments.
- Data Exploration: Data in a Data Lake remains in its native format, preserving its original fidelity. This enables data scientists and analysts to explore data without constraints, applying different processing techniques and schemas as needed.
Building a Resilient Data Lake
Building a resilient and efficient Data Lake can be a complex endeavor. However, there are a few key best practices and technologies you can follow:
- Use Apache Iceberg: Apache Iceberg is an open-source table format that brings ACID transactions to large-scale data platforms. It provides features like schema evolution, snapshot isolation, and time travel, making it ideal for building Data Lakes. By using Iceberg, you ensure data consistency and reliability even as the data scales.
- Use Amazon EMR: Amazon EMR is a cloud-native big data platform that simplifies the deployment and management of big data processing frameworks like Apache Spark, Hive, and Hadoop. EMR can be used to process and transform the data stored in your Data Lake.
- Use Kafka and Debezium: Kafka is a distributed event streaming platform that can be used to ingest data into your Data Lake in real-time. Debezium, on the other hand, is an open-source CDC (Change Data Capture) platform that can capture changes from your relational databases and stream them into Kafka. This allows you to keep your Data Lake up-to-date with the latest changes from your transactional systems.
- Use Glue Catalog: AWS Glue is a fully managed extract, transform, and load (ETL) service that can help you discover, catalog, and transform your data stored in the Data Lake. The Glue Data Catalog serves as a central metadata repository that tracks the data schema and structure, making it easier to manage and query the data.
- Use Trino: Trino is a distributed SQL query engine that can query data stored in a variety of data sources, including Data Lakes, data warehouses, and NoSQL databases. Trino provides a unified view of your data, making it easy to run complex queries across multiple data sources.
HLD for Data Lake:
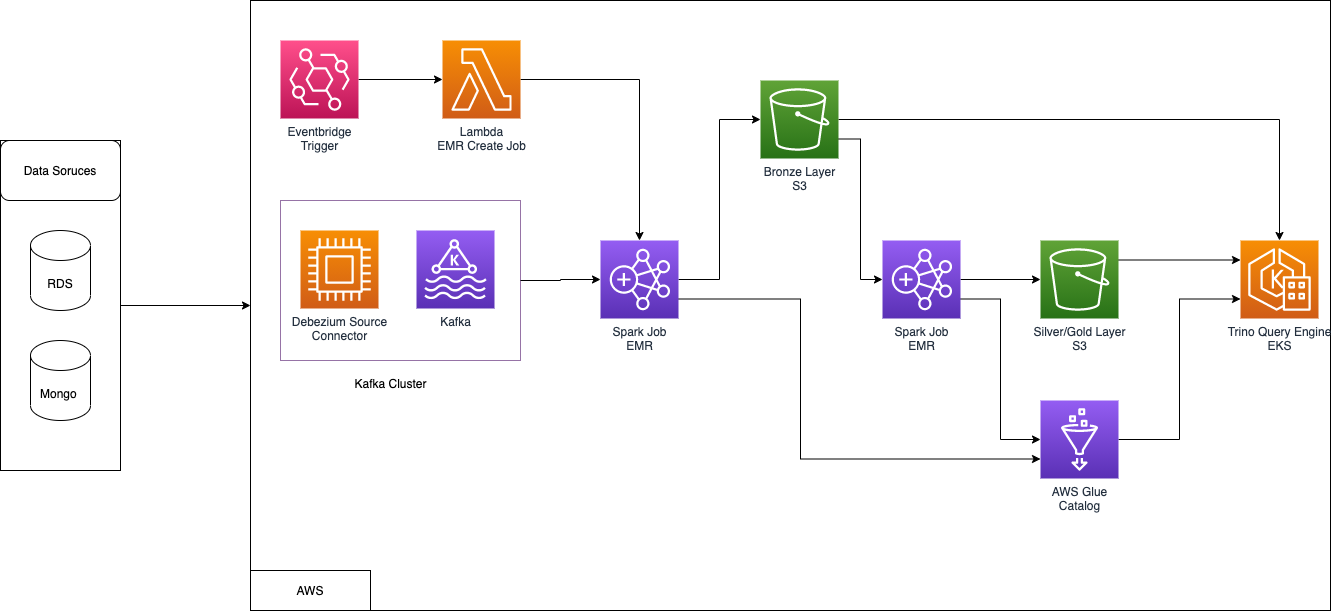
Why do we need EMR as Sink connector?
Replacing a sink connector in Apache Kafka with Amazon Elastic MapReduce (EMR) can be beneficial in certain use cases where you need more complex data processing capabilities, scalability, or specific analytics tasks that go beyond the capabilities of a traditional Kafka sink connector. Here’s a use case that illustrates why you might want to replace a sink connector with EMR:
Use Case: Real-time Log Analytics and Aggregation
Imagine you are running a large e-commerce platform that generates a massive amount of log data from various services and applications. You are using Kafka to collect and process this data in real-time. Initially, you have set up a Kafka sink connector to send the data to a data warehouse for storage and basic analytics.
- Complex Data Transformations: Your data analysis needs evolve, and you require more complex data transformations and aggregations on the incoming data. The Kafka sink connector alone may not be sufficient for these tasks, as it’s primarily designed for simple data routing.
- Scalability: Your data volume increases significantly, and you need a scalable solution to handle the growing amount of data. While Kafka can handle high throughput, processing complex analytics on the data can strain its resources.
- Custom Analytics: You want to perform custom analytics, such as anomaly detection, recommendation systems, and real-time dashboards, which require specialized processing that isn’t easily achievable with a sink connector.
In this scenario, you may decide to replace the Kafka sink connector with Amazon EMR for the following reasons:
Flexible Data Processing: EMR allows you to use tools like Apache Spark, Apache Flink, or Hadoop for more advanced data processing and analytics. You can write custom code and use libraries that are better suited for complex transformations and aggregations.
Scalability: EMR can dynamically scale the number of nodes based on your processing needs. This ensures that you can handle the increasing data volume without compromising performance.
Real-time Analytics: With EMR, you can build real-time analytics pipelines that provide insights into your data as it flows through Kafka. EMR can process data in near-real-time and generate alerts or dashboards to monitor system performance or detect anomalies.
Integration with AWS Ecosystem: EMR seamlessly integrates with other AWS services, such as Amazon S3 for data storage, Amazon Redshift for data warehousing, and Amazon QuickSight for data visualization. This makes it easier to build end-to-end data pipelines and analytics solutions.
Why do we need to use Apache Iceberg instead of Deltalake?
Delta Lake and Apache Iceberg are two popular open-source projects in the realm of big data storage and processing. They both aim to improve data reliability, quality, and performance in data lakes and warehouses, but they have different approaches and features. Here’s a comparison between Delta Lake and Apache Iceberg:
Open Source Community:
- Delta Lake: Delta Lake was developed by Databricks and is tightly integrated with the Apache Spark ecosystem. It has gained significant adoption within the Spark community.
- Apache Iceberg: Apache Iceberg is an independent project under the Apache Software Foundation. It has its own community and is not tied to any specific processing framework, making it more agnostic in terms of technology stack.
Data Lake Compatibility:
- Delta Lake: Delta Lake is primarily designed for data lakes and is tightly integrated with Apache Spark. It adds ACID (Atomicity, Consistency, Isolation, Durability) transactions and schema enforcement capabilities to existing data lakes.
- Apache Iceberg: Apache Iceberg is designed to be storage-layer agnostic, which means it can work with various storage systems, including data lakes, object stores (like AWS S3 and Azure Blob Storage), and Hadoop Distributed File System (HDFS).
ACID Transactions:
- Delta Lake: Delta Lake provides ACID transactions for data lakes. This means it supports atomic writes, consistency, isolation, and durability, ensuring data integrity even in the presence of concurrent read and write operations.
- Apache Iceberg: Apache Iceberg also offers ACID transactions, enabling users to perform atomic and consistent operations on data, which is essential for maintaining data quality and reliability.
Schema Evolution:
- Delta Lake: Delta Lake supports schema evolution, allowing you to easily evolve the schema of your data over time without breaking existing queries or pipelines.
- Apache Iceberg: Apache Iceberg provides advanced schema evolution capabilities, including schema evolution with time travel, which allows you to access historical versions of the schema.
Time Travel:
- Delta Lake: Delta Lake offers time travel features that allow you to query and revert to previous versions of your data, making it useful for auditing and data recovery.
- Apache Iceberg: Apache Iceberg also supports time travel, allowing you to access historical snapshots of your data for auditing and analysis purposes.
Partition Pruning:
- Delta Lake: Delta Lake integrates well with Apache Spark, enabling efficient partition pruning during query execution, which can significantly improve query performance.
- Apache Iceberg: Apache Iceberg also supports partition pruning, making it suitable for query engines like Spark, Hive, and Presto.
Compatibility with Other Tools:
- Delta Lake: Delta Lake is tightly integrated with the Apache Spark ecosystem but may require additional connectors or tools to work with other data processing frameworks.
- Apache Iceberg: Apache Iceberg is more agnostic and can be used with various data processing frameworks and tools beyond just Spark.
Apache Iceberg Image:
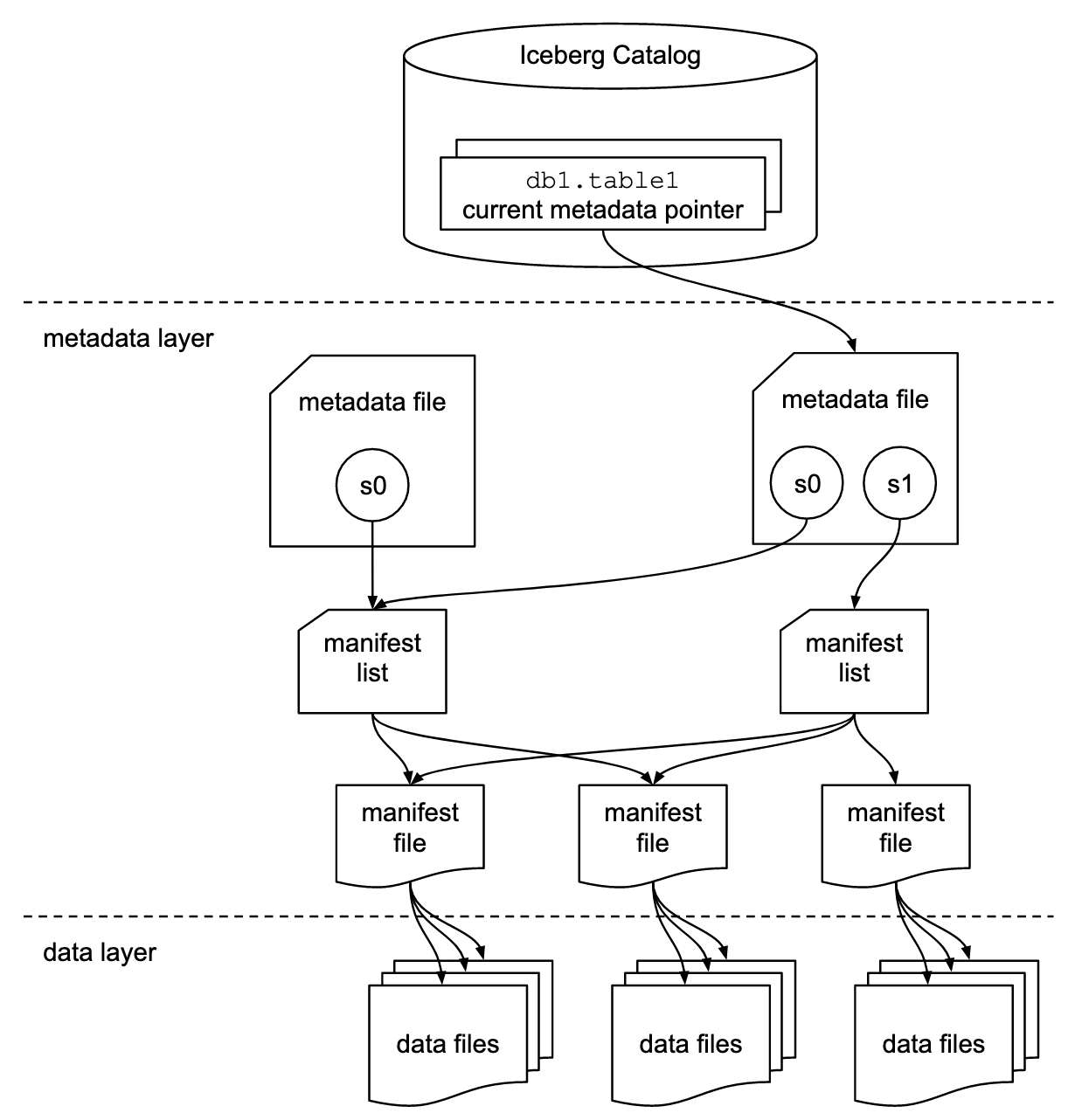
In summary, both Delta Lake and Apache Iceberg offer solutions for managing and improving data quality in data lakes, but they have different focuses and compatibility. Delta Lake is tightly integrated with Spark and is well-suited for Spark-centric environments, while Apache Iceberg is more storage-agnostic and can be used in a wider range of data processing ecosystems, making it a more versatile choice for organizations with diverse data processing needs.
Why do we need to use AWS glue catalog instead of Hive?
AWS Glue Data Catalog and Apache Hive are both metadata repositories that help manage metadata about data stored in a data lake or data warehouse. However, they have some differences in terms of features, integration, and use cases. Here are the benefits of using the AWS Glue Catalog over Hive:
Serverless and Managed Service:
- AWS Glue Catalog: AWS Glue is a serverless and fully managed service. You don’t need to worry about provisioning, scaling, or managing infrastructure. AWS Glue takes care of the catalog’s availability and maintenance, allowing you to focus on your data and analytics.
- Hive: Hive typically requires manual setup and configuration of servers and clusters, which can be complex and time-consuming. It requires ongoing maintenance and monitoring to ensure its availability and performance.
Integration with Other AWS Services:
- AWS Glue Catalog: The Glue Data Catalog seamlessly integrates with other AWS services like AWS Glue ETL for data transformation, Amazon Athena for querying data, and Amazon Redshift Spectrum for extended querying capabilities. This tight integration simplifies the development of end-to-end data pipelines.
- Hive: While Hive can be integrated with AWS services, such as Amazon S3 and Amazon EMR, it may require more manual configuration and management.
Performance Optimization:
- AWS Glue Catalog: AWS Glue automatically generates statistics about the data stored in the catalog. This information is used by query engines like Amazon Athena to optimize query execution plans, improving query performance.
- Hive: In Hive, you often need to manually gather statistics and tune queries for optimal performance, which can be a time-consuming process.
Security and Access Control:
- AWS Glue Catalog: The AWS Glue Catalog integrates with AWS Identity and Access Management (IAM), making it easier to control and manage access to your metadata and data lake resources using AWS security best practices.
- Hive: While Hive also provides access control mechanisms, managing security can be more complex, especially in large-scale deployments.
Scalability:
- AWS Glue Catalog: AWS Glue is designed to scale automatically as your metadata catalog grows, ensuring that it can handle the metadata of large data lakes.
- Hive: The scalability of Hive depends on the underlying infrastructure and cluster configurations, which may require manual adjustments as your data catalog grows.
In summary, the AWS Glue Catalog offers a more streamlined and managed approach to metadata management compared to Hive. It is well-suited for organizations that want to leverage AWS services, simplify metadata management, and focus on analytics rather than infrastructure and maintenance tasks. However, Hive may still be a good choice for organizations with specific requirements or existing Hive deployments that need fine-grained control over their metadata and data processing.
Conclusion:
In the fast-paced world of big data and real-time analytics, the need for scalable and efficient data management solutions has never been greater. As we’ve explored in this blog, leveraging a data lake architecture with Kafka and Amazon EMR as a sink connector can be a game-changer for organizations seeking to harness the power of their data while ensuring scalability, reliability, and flexibility.
By combining Kafka’s real-time streaming capabilities with EMR’s processing muscle, you can build a robust data pipeline that not only ingests vast volumes of data but also transforms, aggregates, and stores it in a scalable data lake. Here are the key takeaways:
1. Real-time Data Ingestion: Kafka excels at ingesting data in real-time, making it the perfect entry point for streaming data into your data lake. Its distributed nature ensures high throughput and low latency, crucial for capturing and processing data as it arrives.
2. Scalability: With EMR, you have the flexibility to scale your data processing resources as needed. As your data volume grows, EMR can seamlessly add more nodes to handle the increased workload, ensuring your data pipeline remains performant.
3. Advanced Processing: EMR brings a wide array of data processing tools and libraries, including Apache Spark and Apache Flink, to the table. These tools enable you to perform complex transformations, aggregations, and analytics on your streaming data, unlocking valuable insights in real-time.
4. Data Lake Flexibility: A data lake built on technologies like Amazon S3 can handle both structured and unstructured data, making it a versatile repository for all your data assets. EMR can interact seamlessly with S3, allowing you to store and retrieve data with ease.
5. Cost Efficiency: By adopting a pay-as-you-go model, EMR offers cost efficiency, as you only pay for the resources you consume. This eliminates the need for overprovisioning infrastructure and allows you to optimize costs as your data processing demands fluctuate.
In conclusion, the combination of a data lake architecture with Kafka as the real-time data ingestion layer and Amazon EMR as the processing and storage powerhouse represents a scalable and powerful solution for modern data-driven organizations. It empowers you to turn your data into actionable insights in real-time, adapt to changing workloads effortlessly, and build a solid foundation for your big data analytics journey. As the data landscape continues to evolve, embracing this scalable data lake architecture is a strategic move towards staying competitive and making the most of your valuable data assets.